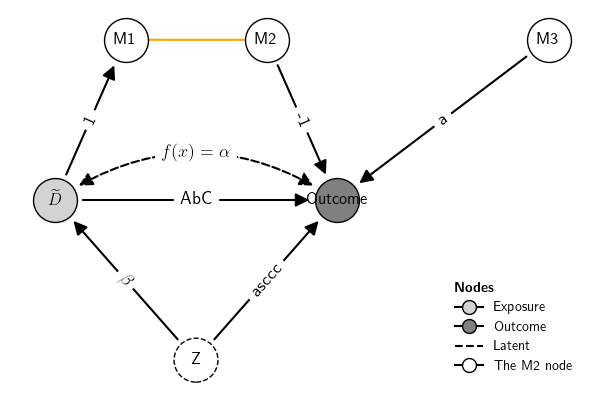
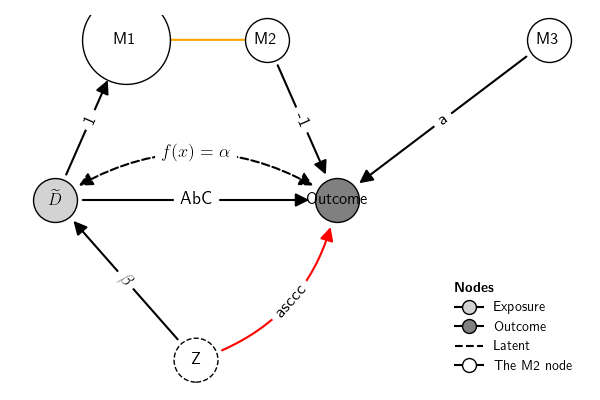
class DAG:
"""
Create a directed acyclic graph (DAG).
Parameters
----------
graph: str, dict, or list
A string with a graph or a list or a dictionary with the edges. Formats:
* String: If string, it can have different formats (see examples)
* X -> Y : directed edge from X to Y
* X -- Y : undirected edge between X and Y
* X <-> Y : bidirected edge between X and Y
* List: If list, the elements are edge types:
* ('X', 'Y'): Tuple becomes X -> Y (directed edge)
* {'X', 'Z'}: Set becomes X -- Y (undirected edge)
* (('X1', 'X2'), ('X2', 'X1')), Tuple of tyuples becomes X <-> Y (bidirected edge)
* Dict: If dictionary, it must contains the edges as elements and the
edge type (directed, undirected, bidirected) as keys. Example:
* 'directed' : [('X', 'Y'), ...] (list of tuples for directed edges)
* 'undirected': [{'X1', 'X2'}, ...] (list of sets fo undirected edges)
* 'bidirected': [ (('X1', 'X2'), ('X2', 'X1')), ...] (list of tuples of tuples of bidirected edges)
data : DataFrame-like or None, optional
Data on the variables included in the graph.
nodes_role : dict[str, Sequence[str]] or None, optional
Keys should be the role of the variables and the dict values strings
or lists with the variable names playing that role.
Main roles for causal analysis are ``'Exposure'``, ``'Outcome'``, and
``'Latent'`` variables.
Other arbitrary roles are accepted, but not used for causal analysis.
nodes_label : dict[str, str] or None, optional
Labels for graph variables. Keys should be variable names, values their labels.
Labels with Latex expression are accepted.
nodes_position : dict[str, tuple[float, float]] or None, optional
Layout coordinates for variables. Keys should be variable names, values
(x, y) coordinate tuples.
edge_label : dict or None, optional
Custom labels for edges. Keys should be edge, values the
edge labels. Latex expression is accepted. See examples below.
Examples
--------
>>> # Examples of acceptable string formats
>>> dag = '''
>>> X1 -> Y
>>> X1 -> Z -> Y
>>> X1 <- X2
>>> '''
>>>
>>> dag = '''
>>> X1 -> A
>>> X1 -> B
>>> X2 -> C
>>> X2 -> D
>>> '''
>>>
>>> dag = '''
>>> X1 -> {A, B}
>>> {C, D} <- X2
>>> '''
>>>
>>> dag = '''
>>> X1 -> {A, B}
>>> X2 -> {C, D}
>>> '''
>>>
>>> dag = '''
>>> # bidirected edge
>>> X3 <-> X4
>>> X3 -- X4 # undirected edge
>>> X5 -- X6 -> X7
>>> '''
>>>
>>>
>>> # basic settings
>>> pos = {'D': (0,0),
>>> 'Y': (1,0),
>>> 'Z': (.5, -1),
>>> 'M1': (.25, 1),
>>> 'M2': (.75, 1),
>>> 'M3': (1.75, 1),
>>> }
>>> roles = {'Exposure' : "D",
>>> 'Outcome' : "Y",
>>> "Latent" : 'Z',
>>> "The M2 node" : "M2" # arbtiraty roles available
>>> }
>>> node_labels = {"D": "$\\widetilde{D}$",
>>> 'Y': "Outcome"}
>>> edge_labels = {
>>> # directed edge labels
>>> ('D', 'M1') : 1,
>>> ('M2', 'Y') : -1,
>>> ('M3', 'Y') : 'a',
>>> ('D', 'Y') : 'AbC',
>>> ('Z', 'D') : '$\\beta$',
>>> ('Z', 'Y'): 'asccc',
>>> # bidirected edge label
>>> (('D', 'Y'), ('Y', 'D')): '$f(x)=\\alpha$',
>>> # undirected edge label
>>> ( 'M1', 'M2' ) : 1234, #
>>> ( 'M2', 'M1' ) : 1234, #
>>> }
>>>
>>>
>>> # using string
>>> # ------------
>>> dag = '''
>>> D -> M1
>>> M1 -- M2
>>> M2 -> Y
>>> M3 -> Y
>>> D <-> Y
>>> D -> Y
>>> Z -> {D, Y}
>>> '''
>>> Gs = gcm.DAG(dag, nodes_role=roles, nodes_position=pos, nodes_label=node_labels, edge_label=edge_labels)
>>> Gs.plot()
>>>
>>> # using a list
>>> # ------------
>>> dag =[('D', 'M1'),
>>> ('M3', 'Y'),
>>> ('M2', 'Y'),
>>> ('D', 'Y'),
>>> ('Z', 'D'),
>>> ('Z', 'Y'),
>>> (('D', 'Y'), ('Y', 'D')),
>>> {'M2', 'M1'}
>>> ]
>>> Gl = gcm.DAG(dag, nodes_role=roles, nodes_position=pos, nodes_label=labels, edge_label=edge_label) #
>>> Gl.plot()
>>>
>>> # using a dict
>>> # ------------
>>> dag = {
>>> 'directed': [
>>> ('D', 'M1'),
>>> ('M3', 'Y'),
>>> ('M2', 'Y'),
>>> ('D', 'Y'),
>>> ('Z', 'D'),
>>> ('Z', 'Y')
>>> ],
>>> 'bidirected': [
>>> (('D', 'Y'), ('Y', 'D'))
>>> ],
>>> 'undirected': [
>>> {'M2', 'M1'}
>>> ]
>>> }
>>> Gd = gcm.DAG(dag, nodes_role=roles, nodes_position=pos, nodes_label=labels, edge_label=edge_label) #
>>> Gd.plot()
Returns
-------
DAG graph object
"""
def __init__(self,
graph,
data=None,
# nodes
nodes_role=None,
nodes_label=None,
nodes_position=None,
# edges
edge_label=None
):
assert graph, "'graph' must be provided."
assert nodes_position is None or isinstance(nodes_position, dict), (
"nodes_position must be None or dict")
assert nodes_label is None or isinstance(nodes_label, dict), (
"nodes_label must be None or dict")
assert nodes_role is None or isinstance(nodes_role, dict), (
"nodes_roles must be None or dict")
# deal with user provided roles in low case
key_roles = ['Outcome', 'Exposure', "Latent"]
if nodes_role:
for role in key_roles:
if role.lower() in nodes_role.keys():
nodes_role[role] = nodes_role[role.lower()]
nodes_role.pop(role.lower())
# graph
self.__graph_list__ = []
self.__graph_dict__ = {}
self.__graph_str_original__ = None
self.__graph_str_parsed__ = None
self.__dagitty__ = None
# edges
self.__edges_str_allowed__ = ['->', '<-', '<->', "--"]
self.edge_label = edge_label or {}
self.directed = []
self.bidirected = []
self.undirected = []
# nodes
self.nodes = set()
self.nodes_parents = {}
self.exposure = []
self.outcome = []
self.latent = []
self.observed = []
self.nodes_role = {}
self.nodes_position = {}
self.nodes_label = {}
self.nodes_info = {}
# keep this order:
self.__build_graph__(graph)
self.__collect_info__(nodes_role, nodes_position, nodes_label)
# dagitty
self.__create_dagitty__()
# others
self.data = data
self.__identification__ = None
# manipulating graph -----------------------------
def get_nodes(self, exclude_latent=False):
"""
Return the graph node names, optionally omitting latent variables.
Parameters
----------
exclude_latent : bool, optional
If ``True``, latent nodes are excluded from the returned list.
Defaults to ``False``.
Returns
-------
list[str]
Node names in the current graph. The order corresponds to the
insertion order preserved in ``self.nodes``.
"""
nodes = list(self.nodes)
latent_nodes = self.latent
if exclude_latent and latent_nodes:
nodes = [n for n in nodes if n not in latent_nodes]
return nodes
def set_node_label(self, nodes_label):
"""
Update display labels for one or more nodes.
Parameters
----------
nodes_label : dict[str, str]
Mapping from node names to their new label strings.
Examples
--------
>>> dag = DAG(graph="X -> Y")
>>> dag.set_node_label({"X": "Treatment (X)", "Y": "Outcome (Y)"})
"""
for node, label in nodes_label.items():
self.nodes_label[node] = label
def set_nodes_role(self, nodes_role):
"""
Create a new DAG instance with updated node roles.
Parameters
----------
nodes_role : dict[str, Sequence[str]]
Keys should be node role names (e.g., ``'Exposure'``, ``'Outcome'``,
``'Latent'``) and values a string or list with the node names.
Lowercase role keys for ``'Exposure'``, ``'Outcome'``, and
``'Latent'`` are automatically promoted to their capitalized equivalents.
Returns
-------
DAG
A fresh `DAG` object reflecting the new role assignments.
Examples
--------
>>> dag = DAG(graph="X -> Y")
>>> updated = dag.set_nodes_role({"Exposure": ["X"], "Outcome": ["Y"]})
>>> updated
Graph:
X -> Y
Observed:
Exposure: X
Outcome: Y
>>> updated.exposure
['X']
"""
res = DAG(graph=self.__graph_str_parsed__,
nodes_role=nodes_role,
nodes_label=self.nodes_label,
nodes_position=self.nodes_position,
edge_label=self.edge_label,
data=self.data)
return res
def set_node_position(self, position):
"""
Assign layout coordinates to nodes in-place.
Parameters
----------
position : dict[str, tuple[float, float]]
Mapping from node names to (x, y) coordinate tuples.
Keys should be the node name, the value its position.
Examples
--------
>>> G = DAG(graph="X -> Y")
>>> G.set_node_position({"X": (0.0, 0.5), "Y": (1.0, 0.5)})
"""
for node, p in position.items():
self.position[node] = p
def edge_add(self, edge):
"""
Add an edge to the graph if it is not already present.
Parameters
----------
edge : tuple[str, str] or tuple[tuple[str, str], tuple[str, str]] or set[str]
Edge specification compatible with the formats accepted at
initialization. Use a two-tuple for directed edges, a set with two
nodes for undirected edges, or a pair of directed tuples for
bidirected edges.
Returns
-------
DAG
The current instance when the edge already exists; otherwise a new
`DAG` instance containing the added edge.
Examples
--------
>>> G = DAG(graph="X -> Y")
>>> G = G.edge_add(("Y", "Z"))
>>> ("Y", "Z") in G.directed
True
"""
res = self
if not self.edge_exist(edge):
graph = self.__graph_list__.copy()
graph.append(edge)
res = self.__rebuild_graph__(graph)
return res
def edge_remove(self, edge):
"""
Remove an existing edge from the graph when present.
Parameters
----------
edge : tuple[str, str] or tuple[tuple[str, str], tuple[str, str]] or set[str]
Edge specification matching one of the accepted formats. The check
is insensitive to direction for bidirected and undirected edges.
Returns
-------
DAG
A new `DAG` instance with the edge removed when the edge exists;
otherwise the current instance is returned unchanged.
Examples
--------
>>> G = DAG(graph="X -> Y")
>>> G = G.edge_remove(("X", "Y"))
>>> ("X", "Y") in G.directed
False
"""
removed = False
graph = self.__graph_list__.copy()
if edge in self.__graph_list__:
graph.remove(edge)
removed = True
elif self.__edge_type__(edge)=='bidirected':
edge = (edge[1], edge[0])
if edge in self.__graph_list__:
graph.remove(edge)
removed = True
if removed:
return self.__rebuild_graph__(graph)
else:
return self
def edge_replace(self, remove, add):
"""
Replace an existing edge with a new one in a single operation.
Parameters
----------
remove : tuple[str, str] or tuple[tuple[str, str], tuple[str, str]] or set[str]
Edge specification to be removed. Formats follow the accepted edge
types for the graph and support undirected and bidirected symmetry.
add : tuple[str, str] or tuple[tuple[str, str], tuple[str, str]] or set[str]
Edge specification to be added after removal.
Returns
-------
DAG
A `DAG` instance reflecting the requested change. If the removal
fails because the edge does not exist, the method still returns the
result of attempting to add the new edge.
Examples
--------
>>> G = DAG(graph="X -> Y")
>>> G = G.edge_replace(("X", "Y"), ("X", "Z"))
>>> ("X", "Y") in G.directed, ("X", "Z") in G.directed
(False, True)
"""
res = self.edge_remove(remove)
res = res.edge_add(add)
return res
def edge_exist(self, edge, edges=None):
"""
Check whether an edge is present in the graph (or a supplied edge list).
Parameters
----------
edge : tuple[str, str] or tuple[tuple[str, str], tuple[str, str]] or set[str]
Edge specification to check for existence. The method canonicalizes
the representation so that undirected and bidirected edges are
insensitive to node order.
edges : list or None, optional
Specific list of edges to search. When ``None``, the method looks up
the corresponding edge collection from the instance.
Returns
-------
bool
``True`` when the edge is found, otherwise ``False``.
Examples
--------
>>> G = DAG(graph="X -> Y")
>>> G.edge_exist(("X", "Y"))
True
>>> G.edge_exist({"X", "Y"})
False
"""
if edges is None:
edge_type = self.__edge_type__(edge)
edges = self.__getattribute__(edge_type)
edges = [edges] if not isinstance(edges, list) else edges
edge = self.__edge_frozen_format__(edge)
edges_in_list = {self.__edge_frozen_format__(e) for e in edges}
return edge in edges_in_list
def set_edge_label(self, edge_label):
"""
Assign or update labels for one or more edges.
Parameters
----------
edge_label : dict
Mapping of edge specifications to label values. Keys can be any
valid edge representation accepted at initialization. Values are
stored verbatim without validation.
Examples
--------
>>> G = DAG(graph="X -> Y")
>>> G.set_edge_label({("X", "Y"): "beta"})
>>> G.edge_label[("X", "Y")]
'beta'
"""
for edge, label in edge_label.items():
self.edge_label[edge] = label
# computations --------------------------------------
# dagitty (R dependencies)
def dseparated(self, var1=None, var2=None, conditional=None):
"""
Determine whether two variables are d-separated given a conditioning set.
Parameters
----------
var1 : str
Name of the first variable.
var2 : str
Name of the second variable.
conditional : Sequence[str] or None, optional
Variables to condition on. Provide an iterable of node names. When
``None``, no conditioning is applied.
Returns
-------
bool
``True`` if the variables are d-separated given ``conditional``,
otherwise ``False``.
Examples
--------
>>> G = DAG(graph="X -> Z -> Y")
>>> G.dseparated("X", "Y")
False
>>> G.dseparated("X", "Y", conditional=["Z"])
True
"""
assert var1 and isinstance(var1, str), "'var1' (a str) must be provided."
assert var2 and isinstance(var2, str), "'var2' (a str) must be provided."
if conditional is None:
conditional = NULL
res = dagitty.dseparated(self.__dagitty__, X = var1, Y = var2, Z=conditional)[0]
return res
# dagitty (R dependencies)
def dseparation(self, var1, var2):
"""
Retrieve the list of d-separations involving two variables.
Parameters
----------
var1 : str
Name of the first variable.
var2 : str
Name of the second variable.
Returns
-------
list[list[str]] or None
Conditioning sets that d-separate ``var1`` and ``var2``. Each inner
list contains the conditioning variables as strings. Returns
``None`` when no separating set is found.
Examples
--------
>>> G = DAG(graph="X -> Z -> Y")
>>> G.dseparation("X", "Y")
[['Z']]
"""
assert var1 and isinstance(var1, str), "'var1' (a str) must be provided."
assert var2 and isinstance(var2, str), "'var2' (a str) must be provided."
res = self.local_independencies()
if res.nrow>0:
res = (
res
.separate('term', into=['var1', 'var2|conditional'], sep='_||_', remove=False)
.separate('var2|conditional', into=['var2', 'conditional'], sep=' | ', remove=True) #
.mutate(var1 = tp.str_trim('var1'),
var2 = tp.str_trim('var2'),
conditional = tp.str_trim('conditional'),
)
.replace_null({'conditional':''})
.filter(((tp.col("var1")==var1) & (tp.col('var2')==var2)) |
((tp.col("var2")==var1) & (tp.col('var1')==var2))
)
)
res = res.pull('conditional')
res = [s.split(',') for s in res]
res = [[string.strip() for string in inner_list] for inner_list in res]
else:
print(f'Not possible to d-separate {var1} and {var2} in the graph.')
res = None
return res
# dagitty (R dependencies)
def local_independencies(self, data=None, alpha=0.05, include_sep_cols=False):
"""
List conditional independencies implied by the DAG, and test them if data is provided.
Parameters
----------
data : tidypolars4sci.DataFrame or None, optional
Observational data used to perform local conditional independence
tests through ``dagitty::localTests``. When ``None`` (default), the
method enumerates implied independencies analytically.
alpha : float, optional
Significance level for converting quantile-based confidence bounds
into standard errors. Only used when ``data`` is provided. Defaults
to 0.05.
include_sep_cols : bool, optional
When ``True``, return additional columns detailing the separated
variables and conditioning sets. Defaults to ``False``.
Returns
-------
tidypolars4sci.DataFrame
Tidy representation of the implied independencies. The result
always includes columns ``term`` (formatted as ``"Y _||_ X | Z"``),
``estimate``, ``se``, ``lo``, ``hi``, and ``pvalue``. When
``include_sep_cols`` is ``True``, columns ``var1``, ``var2``, and
``cond`` are also present.
Examples
--------
>>> G = DAG(graph="X -> Z -> Y")
>>> independencies = G.local_independencies(include_sep_cols=True)
>>> independencies.pull("term").to_list()
['Y _||_ X | Z']
"""
if data is None:
data = self.data
# compute
if data is None:
inds = dagitty.impliedConditionalIndependencies(self.__dagitty__)
res = tp.tibble()
for ind in inds:
y = ind[0][0]
x = ind[1][0]
z = ind[2]
term = f"{y} _||_ {x}"
term = f"{term} | {', '.join(z)}" if z else term
tmp = tp.tibble({'term': [term],
"var1": [y],
"var2": [x],
"cond": [z]})
res = res.bind_rows(tmp)
inds = res
else:
inds = dagitty.localTests(self.__dagitty__, data=convert().tp2tibble(data), abbreviate_names=False)
z = dnorm.ppf(1-alpha/2)
inds = convert().rtibble2tp(inds, rownames2col='term')\
.rename({'p.value':"pvalue",
'2.5%':'lo',
'97.5%':'hi',
})\
.mutate(se = ( tp.col('hi')-tp.col('lo') ) / (2*z) )
if inds.nrow>0:
inds = (
inds
.separate('term', into=['var1', 'var2_cond'], sep='_||_', remove=False)
.separate('var2_cond', into=['var2', 'cond'], sep='|')
)
vars = ['term', 'estimate', 'se', 'lo', 'hi', 'pvalue']
if include_sep_cols:
vars += ['var1', 'var2', 'cond']
inds = inds.select(vars)
return inds
# dagitty (R dependencies)
def identification_analysis(self, exposure=None, outcome=None,
conditional = None,
causal_probability='maybe',
iv='maybe',
verbose=True
):
"""
Run identification analysis for the specified exposure-outcome pair.
Parameters
----------
exposure : str or list[str] or None, optional
Exposure variable(s) of interest. When ``None``, the current DAG
exposure roles are used.
outcome : str or None, optional
Outcome variable. Defaults to the first DAG outcome role when
omitted.
conditional : str or list[str] or None, optional
Variables to condition the causal effect on. Strings are promoted to
single-element lists.
causal_probability : {'always', 'maybe'}, optional
Controls whether causal probabilities are computed. With ``'maybe'``
(default) probabilities are evaluated only when identification by
adjustment fails; ``'always'`` forces computation.
iv : {'always', 'maybe'}, optional
Identification using instrumental variable. Use ``'maybe'`` (default)
to run analysis only when identification by
adjustment fails; use ``'always'`` to force IV evaluation.
verbose : bool, optional
When ``True`` (default), results are printed via ``self.print``.
Returns
-------
None
Notes
-----
Results printed and can be retrieved using <DAG>.identification
and <dag>.print(). See examples.
Examples
--------
>>> G = DAG(graph="X -> Y")
>>> G.identification_analysis(exposure="X", outcome="Y", verbose=False)
>>> G.identification_analysis(exposure="X", outcome="Y", verbose=False)
>>> G.identification() # to print
>>> G.print('identification') # to print
>>> G.identification_dict # dictionary
"""
assert not outcome or isinstance(outcome, str), 'Outcome must be a string.'
assert not exposure or (isinstance(exposure, str) or isinstance(exposure, list)), 'Exposure must be a string or list.'
assert outcome or self.outcome, "No outcome found."
assert exposure or self.exposure, "No exposure found."
exposure = exposure or self.exposure
outcome = outcome or self.outcome[0]
conditional = [conditional] if isinstance(conditional, str) else conditional
assert exposure is not None, "Exposure must be provided."
assert outcome is not None, "Outcome must be provided."
self.__identification__ = identification(G=self,
exposure = exposure,
outcome = outcome,
conditional = conditional,
causal_probability = causal_probability,
iv = iv,
verbose=verbose)
if verbose:
self.print('identification')
return None
def get_identified(self, by='parameter', include_all=False):
# """
# Retrieve identification results summarised by parameter or strategy.
# Parameters
# ----------
# by : {'parameter', 'strategy'}, optional
# Grouping used for the returned results. Defaults to ``'parameter'``.
# include_all : bool, optional
# When ``True``, include all strategies that identify the parameters.
# Otherwise, only the SoO, or IV, or do-calculus, whatever
# identifies it first. Defaults to ``False``.
# Returns
# -------
# dict
# Examples
# --------
# >>> G = DAG(graph="X -> Y")
# >>> G.identification_analysis(exposure="X", outcome="Y", verbose=False)
# >>> G.get_identified()
# """
if not self.__identification__:
self.identification_analysis()
res = self.__identification__.get_identified(by=by, include_all=include_all)
return res
def identification(self, print='default', parameter='ACE', *args, **kws):
# """
# Print identification analysis using custom output options.
# Parameters
# ----------
# print : str, optional
# Content selector forwarded to the identification printer. Defaults
# to ``'default'``.
# parameter : str, optional
# Target causal parameter to display, e.g., ``'ACE'`` (default).
# *args :
# Additional positional arguments forwarded to ``self.print``.
# **kws :
# Keyword arguments supporting an ``identification`` dictionary that
# overrides default print options.
# Returns
# -------
# None
# Examples
# --------
# >>> G = DAG(graph="X -> Y")
# >>> G.identification_analysis(exposure="X", outcome="Y", verbose=False)
# >>> G.identification(print="assumptions", parameter="ACE")
# """
if not self.__identification__:
self.identification_analysis(verbose=False)
identification = kws.get("identification", {})
identification["content"] = print
identification["parameter"] = parameter
self.print('identification', identification=identification)
return None
@property
def identification_dict(self):
"""
Mapping of identification results produced by the most recent run of
identification_analysis.
Returns
-------
dict
Identification summary as generated by the internal identification
object.
Examples
--------
>>> G = DAG(graph="X -> Y")
>>> G.identification_analysis(exposure="X", outcome="Y", verbose=False)
>>> isinstance(G.identification_dict, dict)
True
"""
if not self.__identification__:
self.identification_analysis()
res = self.__identification__.identification
return res
def print(self,
what = 'graph',
identification = dict(
content='default',
style='text',
strategy = 'all',
parameter = 'ACE',
omit_DAG=True,
print_assumptions=None,
print_assumptions_verbose=None
)
):
"""
Display graph or identification information using configured options.
Parameters
----------
what : {'graph', 'DAG', 'dag', 'identification'}, optional
Content selector. Case-insensitive variants for graph display are
accepted. Defaults to ``'graph'``.
identification : dict, optional
Print configuration dict forwarded to the internal identification
object. Missing keys fall back to global defaults obtained from
``get_options()``.
Returns
-------
None
Examples
--------
>>> G = DAG(graph="X -> Y")
>>> G.print(what="graph")
>>> G.identification_analysis(exposure="X", outcome="Y", verbose=False)
>>> G.print(what="identification", identification={"content": "strategy"})
"""
if what in ['graph', 'DAG', 'dag']:
print(self)
if what=='identification':
ops = identification.copy()
# defaults
pars = ["print_assumptions", "print_assumptions_verbose"]
for par in pars:
if ops.get(par, None) is None:
ops[par] = get_options()[par]
if not self.__identification__:
self.identification_analysis()
self.__identification__.print(**identification)
self.__identification__.__assumptions_print__(category='identification', **ops)
return None
# dagitty (R dependencies)
def paths(self, exposure=None, outcome=None, adj_set=None, directed=False):
"""
Get paths between exposure and outcome, optionally conditioning on a set.
Parameters
----------
exposure : str or list[str] or None, optional
Exposure node(s). Defaults to the DAG's exposure role when omitted.
outcome : str or list[str] or None, optional
Outcome node(s). Defaults to the DAG's outcome role when omitted.
adj_set : Sequence[str] or None, optional
Conditioning set supplied to ``dagitty.paths``. ``None`` is passed
through to indicate no adjustment.
directed : bool, optional
When ``True``, restrict to directed paths from exposure to outcome.
Defaults to ``False``.
Returns
-------
dict[str, dict[str, Any]]
Mapping from path strings to dictionaries with keys ``'open'`` and
``'adj_set'`` indicating path status and conditioning set.
Examples
--------
>>> G = DAG(graph="X -> Z -> Y")
>>> G.paths(exposure="X", outcome="Y", directed=True)
{'X -> Z -> Y': {'open': True, 'adj_set': None}}
"""
exposure = exposure or self.exposure
outcome = outcome or self.outcome
assert exposure, "Exposure must be provided."
assert outcome, "Outcome must be provided."
adj = adj_set or NULL
paths_info = dagitty.paths(self.__dagitty__, exposure, to=outcome, Z=adj, directed=directed)
paths = list(paths_info.rx2['paths'])
are_open = list(paths_info.rx2['open'])
return {path:{'open':is_open, 'adj_set':adj_set} for path, is_open in zip(paths, are_open)}
def mediators(self, as_string=False):
"""
Extract mediator nodes lying on directed paths from exposure to outcome.
Parameters
----------
as_string : bool, optional
When ``True``, return a formatted string representation of mediator
sets. Defaults to ``False`` to return a list of lists.
Returns
-------
list[list[str]] or str
Mediator nodes grouped by directed path when ``as_string`` is
``False``; otherwise a string representation of the same structure.
Examples
--------
>>> G = DAG(graph="X -> M -> Y")
>>> G.mediators()
[['M']]
>>> G.mediators(as_string=True)
'[[M]]'
"""
paths = self.paths(directed=True)
paths = [p.split('->') for p in paths]
exposure = self.exposure
outcome = self.outcome
res = []
for path in paths:
res += [[var.strip() for var in path if var.strip() not in exposure + outcome]]
res = [l for l in res if len(l)>0]
if as_string:
res = f"[{', '.join([f"[{', '.join(l) }]" for l in res])}]"
return res
# dagitty (R dependencies)
def equivalence_class(self):
"""
Construct the partially directed equivalence class implied by the DAG.
Returns
-------
DAG
A new `DAG` instance representing the Markov equivalence class,
where edges are undirected unless compelled by v-structures.
Notes
-----
The equivalence class replaces directional edges with undirected edges
except in v-structures (triples ``X -> Z <- Y`` where ``X`` and ``Y``
are not adjacent).
Examples
--------
>>> G = DAG(graph="X -> Z -> Y")
>>> eq = G.equivalence_class()
>>> eq
Graph:
Z -- X
Z -- Y
Observed: Z, Y, X
>>> eq.undirected
[{'X', 'Z'}, {'Z', 'Y'}]
"""
eq = dagitty.equivalenceClass(self.__dagitty__)
dag, _ = self.__dagitty2inputs__(eq)
res = self.__rebuild_graph__(dag)
return res
# dagitty (R dependencies)
def equivalent_dags(self):
"""
Generate all DAGs that are Markov equivalent to the current graph.
Returns
-------
list[DAG]
Collection of `DAG` instances, each representing a distinct DAG in
the equivalence class.
Examples
--------
>>> G = DAG(graph="X -> Z -> Y")
>>> dags = G.equivalent_dags()
>>> len(dags)
3
"""
eqs = dagitty.equivalentDAGs(self.__dagitty__)
res = []
for eq in eqs:
dag, _ = self.__dagitty2inputs__(eq)
res += [self.__rebuild_graph__(dag)]
return res
def observationally_equivalent(self, G):
"""
Test whether two DAGs are observationally equivalent. See details.
Parameters
----------
G : DAG
Graph to compare with the current instance.
Returns
-------
bool
``True`` if both graphs encode the same observational constraints,
i.e., they belong to the same Markov equivalence class; ``False``
otherwise.
Details
-------
The method checks if two DAGs are observationally equivalent by comparing their Markov equivalent classes.
The method considers only the DAG structure, that is, CBN or SCM when no functional
form for the latter is selected. Observational equivalence is related to Markov equivalence.
Two DAGs are Markov equivalent if and only if
* They have the same skeleton (same set of adjacencies, i.e., same undirected edges)
* They have the same set of v-structures (triples $ X -> Z <- Y $ where X and Y are not adjacent).
An equivalence class of a DAG is a graph that replaces directional edges with undirected edges except
in v-structures. Therefore, all Markov equivalent DAGs will have the same equivalence class.
**For CBN:**
- Two CBNs are observationally equivalent if and only if they are Markov equivalent.
**For SCM:**
*SCM without functional form assumptions*, for observational equivalence to hold:
- Necessary condition: both SCMs have the same set of conditional independencies.
- Sufficient condition: both SCMs are in the same Markov equivalence class (Pearl, 2009).
Basically, two SCMs without imposing any functional form assumptions to either
are observationally equivalent if and only if their causal graphs belong to the same Markov
equivalence class --- i.e., they share the same skeleton and v-structures.
*SCM with functional form assumptions:*
- Once you impose functional form restrictions on SCMs, such as linearity, Gaussian disturbance, or
additive error, observational equivalence can be strictly finer.
That is, Markov equivalence is not a sufficient condition.
**Examples:**
* *Linear Gaussian SEMs assumption:* All DAGs in the same equivalence class remain indistinguishable.
Markov equivalence implies observational equivalence and vice-versa. Reason: any covariance matrix that
one DAG can generate can also be generated by another DAG in its equivalence class, via suitable
parameter choice.
* *Linear non-Gaussian models (LiNGAM):* Orientations become testable because independent
non-Gaussian noise 'pins down' which variable must be the parent, breaking Markov equivalence.
Example: $X \\rightarrow Y$ and $X \\leftarrow Y$: In the Gaussian case: indistinguishable.
In non-Gaussian: distinguishable.
* *Additive Noise Models (ANMs):* - If the true relation is $ Y = f(X) + e $ with independent
noise $ e $, then typically the 'wrong' orientation $ X = g(Y) + e' $ cannot hold with
independent noise. So direction becomes identifiable.
In summary, generally, for *SCMs with no distributional restrictions*, Markov equivalence
imply observational equivalence. But once you impose restrictions via functional forms
or noise properties to the SCMs (linear, Gaussian, additive, etc.),
observational equivalence can be strictly finer than Markov equivalence, and
one may be able to distinguish empirically two DAGs inside the same Markov equivalence class.
Some Markov-equivalent DAGs become distinguishable. Therefore, as the
observational equivalence between Markov equivalent DAGs depends on the functional
form assumption adopted, the evaluation is case-by-case.
Examples
--------
>>> G1 = DAG(graph="X -> Y")
>>> G2 = DAG(graph="X <- Y")
>>> G1.observationally_equivalent(G2)
True
References
----------
* Pearl, J. (2009). *Causality: Models, Reasoning and Inference*. Cambridge University Press.
"""
# check if same equivalence class
G1_eq = self.equivalence_class()
G2_eq = G.equivalence_class()
diff = G1_eq.edge_differences(G2_eq)
obs_eq = True
for g, edges in diff.items():
obs_eq &= all([len(e)==0 for e in edges.values()])
return obs_eq
def assumptions(self, category=None, verbose=False, assumption_type=None):
"""
Retrieve identification assumptions grouped by category.
Parameters
----------
category : str or None, optional
Filter assumptions to a specific category (e.g., ``'identification'``).
When ``None`` (default), all available categories are returned.
verbose : bool, optional
If ``True``, include additional descriptive information when supported
by the underlying identification object. Defaults to ``False``.
assumption_type : str or None, optional
Filter assumptions to ``'causal'`` or ``'statistical'``.
Returns
-------
list[str] or None
Requested assumption definitions, or verbose assumption summaries
when ``verbose=True``. Returns ``None`` when filters are invalid.
Examples
--------
>>> G = DAG(graph="X -> Y")
>>> G.identification_analysis(exposure="X", outcome="Y", verbose=False)
>>> G.assumptions(category="identification")
"""
if not self.__identification__:
self.identification_analysis()
return self.__identification__.assumptions(
category=category, verbose=verbose, assumption_type=assumption_type
)
# -------------------------------------------------
# plots -------------------------------------------
def plot(self,
# nodes
graph_style = None,
nodes_label=None,
nodes_position=None,
estimates=None,
# node
node_subset=None,
node_shape=None,
node_size = None,
node_color = None,
node_border_color=None,
node_border_style=None,
node_border_width=None,
node_latent_show=True,
# node label
show_labels = True,
use_labels = True,
node_label_color='black',
node_label_fontsize=None,
node_label_fontweight='normal',
node_label_adj_x=0,
node_label_adj_y=0,
node_label_box=None,
node_label_box_style="square",
node_label_box_margin=.5,
# edges
edge_subset=None,
edge_color=None,
edge_style=None,
edge_arc = None,
edge_linewidth = None,
edge_head_size = None,
edge_head_style = None,
edge_margin_tail=None,
edge_margin_head=None,
# edges labels
edge_label=None,
edge_label_color_background='white',
edge_label_color_border='white',
edge_label_size=None,
edge_label_color=None,
edge_label_alpha=None,
edge_label_rotate=None,
edge_label_position=None,
edge_label_estimates_sig_level=0.05,
edge_label_estimates_colors={"negative":"red", "positive":"blue"},
edge_label_estimates_face=None,
edge_label_estimates_show_sig=True,
edge_label_estimates_show_sig_alpha={"Yes": 1, "No": .2},
edge_label_estimates_show_ci=False,
edge_label_estimates_show_ci_round=4,
edge_label_pvalue=None,
edge_label_font_family = None,
# legend
legend_show=True,
legend_title='Nodes',
legend_title_align='left',
legend_title_weight='bold',
legend_title_size=12,
legend_omit_cases=['Observed'],
legend_keys=None,
legend_loc='best',
legend_fontsize=10,
legend_frame=False,
legend_kws={},
#
title = None,
title_loc = 'left',
title_kws = {},
#
figsize = [6, 4],
usetex = True,
latex_packages = None,
ax=None,
show_plot=None,
*args,
**kws
):
"""
Render the DAG using matplotlib with extensive styling controls.
Parameters
----------
graph_style : dict, str, None, optional
If str, it must be a name of a predefined built-in style
(see causalinf.gcm.styles()). When ``None``, falls
back to the global plotting option. If dict, it must
match the names of the keys of the built-in styles
(see causalinf.gcm.styles(which='default')).
nodes_label : dict[str, str] or None, optional
Mapping from node names to display labels.
nodes_position : dict[str, tuple[float, float]] or None, optional
Coordinates to override automatic layout positions.
estimates : estimate or None, optional
Output of ``causalinf.scm.estimate`` used to annotate edges with
estimates and p-values.
node_subset : dict[str, list[str]] or None, optional
Restrict plotting to specific node groups (e.g., observed,
latent). Defaults to all nodes.
node_latent_show : bool, optional
If ``False``, omit latent nodes while preserving their effects via
arcs. Defaults to ``True``.
show_labels : bool, optional
Display node labels when ``True`` (default).
use_labels : bool, optional
When ``True`` (default), prefer custom labels over node names.
node_ : dict or scalar or None, optional
Control the visual attributes of nodes. Can be applied per node,
per group based on node role, or to all nodes.
Which case happends depends on the input:
* str, float, int -> apply to all nodes
* None -> use defaults based on GCM styles by type (see causalinf.gcm.styles())
* dict -> apply to nodes or types based on the keys, which can be:
- Node Role: 'Exposure', "Outcome", "Latent", "Observed", or any user-defined node role
- Node name
Accepted values for each parameter:
* _shape: ``str``
* _size: int, ``float``
* _color: ``str``
* _border_color: ``str``
* _border_style: ``str`` ('-', 'solid', '--', 'dashed', ":", 'dotted')
* _border_width: ``int, float``
* _label_color: ``str``
* _label_fontsize: ``int, float``
* _label_fontweight: ``str`` (normal, bold, italic)
* _label_adj_x: int, ``float``
* _label_adj_y: int, ``float``
* _label_box_style: ``str`` ("round"')
* _label_box_margin: ``int, float``
node_latent_show: bool
If True, show latent nodes
node_label_box: bool, optional
If True, draw box around the label when using 'rectangle' node style.
edge_ : dict or scalar or None, optional
Control the visual attributes of edges. Can be applied per edge,
per edge type, or to all edges. Which case happends depends on the input:
- scalar -> apply to all edges
- None -> use defaults by edge type
- dict -> keys can be:
* edge type (case-insensitive):
* 'directed' -> apply to all directed edges
* 'bidirected' -> apply to all bidirected edges
* 'undirected' -> apply to all undirected edges
* actual edges. Example:
- ('D', 'Y') apply to the "D -> Y" directed edge
- (('D', 'Y'), ('Y', 'D')) apply to the "D <-> Y" bidirected edge
- frozenset({'D', 'Y'}) apply to the "D -- Y" undirected edge
Accepted values for each parameter:
* _color: ``str``
* _style: ``str`` ('-', 'solid', '--', 'dashed', ":", 'dotted')
* _arc: ``float``
* _linewidth: ``float``
* _head_size: ``float``
* _head_style: ``str`` ('->', '-|>')
* _margin_tail: ``float``
* _margin_head: ``float``
* _label: ``str``
* _label_color_background: ``str``
* _label_color_border: ``str``
* _label_size: ``float``
* _label_color: ``str``
* _label_alpha: ``float``
* _label_rotate: bool
* _label_position: ``float``
edge_subset : dict[str, list] or None, optional
Limit plotting to selected edges by type.
edge_label_estimates_sig_level : float, optional
Significance level used when estimates include confidence bounds.
edge_label_estimates_colors : dict or None, optional
Colors for negative and positive estimate labels. Use ``None`` to
keep the default edge label color. Defaults to
``{"negative": "red", "positive": "blue"}``.
edge_label_estimates_face : dict or None, optional
Font weight for negative and positive estimate labels, e.g.
``{"negative": "normal", "positive": "bold"}``. Use ``None`` to
keep the normal label weight.
edge_label_estimates_show_sig : bool, optional
Append significance stars from the estimates summary when ``True``.
Defaults to ``True``.
edge_label_estimates_show_sig_alpha : dict or None, optional
Alpha values keyed by ``"Yes"`` and ``"No"``, where ``"Yes"``
means the estimate p-value is at or below
``edge_label_estimates_sig_level``. Use ``None`` to keep the
default edge label alpha. Defaults to ``{"Yes": .5, "No": 1}``.
edge_label_estimates_show_ci : bool, optional
Add confidence intervals below the estimate label when ``True``.
Defaults to ``False``.
edge_label_estimates_show_ci_round : int, optional
Number of decimal places used for confidence interval bounds.
Defaults to ``4``.
edge_label_pvalue : dict or None, optional
P-value annotations keyed by edge.
edge_label_font_family : str or None, optional
Font family for edge labels.
legend_show : bool, optional
Display the legend when ``True`` (default).
legend_title : str, optional
Legend title. Defaults to ``'Nodes'``.
legend_title_align : {'left', 'center', 'right'}, optional
Horizontal alignment for the legend title.
legend_title_weight : str, optional
Font weight for the legend title.
legend_title_size : int, optional
Legend title font size.
legend_omit_cases : list[str], optional
Node role labels to omit from the legend.
legend_keys : dict or None, optional
Custom legend entries keyed by role.
legend_loc : str, optional
Legend placement for ``matplotlib.axes.Axes.legend``.
legend_fontsize : int, optional
Legend text size.
legend_frame : bool, optional
Draw a frame around the legend when ``True``.
legend_kws : dict, optional
Additional keyword arguments forwarded to ``legend``.
title : str or None, optional
Plot title.
title_loc : {'left', 'center', 'right'}, optional
Title alignment. Defaults to ``'left'``.
title_kws : dict, optional
Additional title styling options.
figsize : Sequence[float], optional
Width and height (in inches) for the created figure. Defaults to
``[6, 4]``.
usetex : bool, optional
Enable LaTeX rendering for text. Defaults to ``True``.
ax : matplotlib.axes.Axes or None, optional
Existing axis to draw on. A new figure and axis are created when
``None``.
show_plot : bool or None, optional
Override global option controlling whether ``plt.show()`` is called.
*args :
Additional positional arguments forwarded to the internal plotting
helpers.
**kws :
Extra keyword arguments forwarded to the internal plotting helpers.
Returns
-------
matplotlib.axes.Axes
plot object and axis on which the graph is drawn.
Examples
--------
>>> G = DAG(graph="X -> Y")
>>> plt, ax = G.plot(figsize=(4, 3), show_plot=False)
True
>>> dag = '''
>>> D -> M1
>>> M1 -- M2
>>> M2 -> Y
>>> M3 -> Y
>>> D <-> Y
>>> D -> Y
>>> Z -> {D, Y}
>>> '''
>>> pos = {'D': (0,0),
>>> 'Y': (1,0),
>>> 'Z': (.5, -1),
>>> 'M1': (.25, 1),
>>> 'M2': (.75, 1),
>>> 'M3': (1.75, 1),
>>> }
>>> pos2 = {'D': (.5,0),
>>> 'Y': (1,0),
>>> 'Z': (.5, -1),
>>> 'M1': (.25, 1),
>>> 'M2': (.75, 1),
>>> 'M3': (1.75, 1),
>>> }
>>> roles = {'Exposure': "D",
>>> 'Outcome' : "Y",
>>> "Latent" : 'Z',
>>> "M2 role" : "M2"
>>> }
>>> labels = {"D": "$\widetilde{D}$",
>>> "M1":'$M_1$',
>>> 'Y': "Outcome"}
>>> labels2 = {"D": "$\widetilde{D}_i$"}
>>> edge_label = {('D', 'M1') : 1,
>>> ('M2', 'Y') : -1,
>>> ('M3', 'Y') : 'a',
>>> ('D', 'Y') : 'bsd;fkajsd;',
>>> ('Z', 'D') : '$\\beta$',
>>> ('Z', 'Y'): 'asccc',
>>> (('D', 'Y'), ('Y', 'D')): 'abc',
>>> # ('M2', 'M1') : 1234, # no label for undireted edges
>>> }
>>>
>>> G = gcm.DAG(dag, nodes_role=roles, nodes_position=pos, nodes_label=labels) #
>>> G.plot()
>>>
>>> G.plot(node_color='red')
>>> G.plot(node_color={'D':'red'})
>>> G.plot(node_border_color={'D':'red'})
>>> G.plot(node_border_color={'Z':'red'})
>>> G.plot(node_border_color={'Z':'red'}, node_border_style={'D':':'})
>>> G.plot(node_border_color={'Z':'red'}, node_border_style={'D':':', 'Z':'solid'})
"""
from . import scm as causalinf_scm
assert estimates is None or isinstance(estimates, causalinf_scm.estimate), (
"'estimates' must be either None or an object of causalinf.scm.estimate ")
assert isinstance(latex_packages, list) or latex_packages is None, "latex_packages must be None or a list"
default_usetex = plt.rcParams["text.usetex"]
plt.rcParams["text.usetex"] = usetex
latex_packages_base = ["amsmath", "amssymb", "siunitx", "bm", "wasysym", "marvosym"]
packages = latex_packages_base + (latex_packages or [])
plt.rcParams['text.latex.preamble'] = rf"\usepackage{{{', '.join(packages)}}}"
show_plot = show_plot if not None else get_options('show_plot')
# collect arguments
pars = dict(locals()) # {'node_position':..., 'arg2':..., 'args':(...), 'kws':{...}}
args = pars.pop('args') # extra positional
kws = pars.pop('kws') # extra keyword
estimate_label_sign = {}
estimate_label_pvalue = {}
# use estimates as labels
if estimates is not None:
edge_label, edge_label_pvalue, estimate_label_sign = (
self.__plot_collect_labels_estimate__(
estimates,
show_sig=edge_label_estimates_show_sig,
show_ci=edge_label_estimates_show_ci,
show_ci_round=edge_label_estimates_show_ci_round
)
)
estimate_label_pvalue = edge_label_pvalue
# figure
# ------
G_draw = self.__plot_create_nx__()
if ax is None:
fig, ax = plt.subplots(figsize=figsize, tight_layout=True)
plt.sca(ax)
# styles
# ------
graph_style = graph_style or get_options('graph_style')
style_dict = resolve_graph_style(graph_style, GRAPH_STYLES)
# nodes
# -----
node_subset = self.__plot_nodes_subset__(node_subset, node_latent_show)
nodes_position = self.__plot_nodes_positions__(G_draw, nodes_position)
node_size = self._plot_parse_aes_node('node_size', node_size, style_dict)
node_color = self._plot_parse_aes_node('node_color', node_color, style_dict)
node_shape = self._plot_parse_aes_node('node_shape', node_shape, style_dict)
node_border_width = self._plot_parse_aes_node('node_border_width', node_border_width, style_dict)
node_border_color = self._plot_parse_aes_node('node_border_color', node_border_color, style_dict)
node_border_style = self._plot_parse_aes_node("node_border_style", node_border_style, style_dict)
for _, nodes in node_subset.items():
for node in nodes:
fig_nodes = nx.draw_networkx_nodes(
G_draw,
nodes_position,
nodelist=[node],
ax=ax,
#
node_size = node_size[node],
node_color = node_color[node],
node_shape = node_shape[node],
linewidths = node_border_width[node],
edgecolors = node_border_color[node],
alpha = None,
cmap = None,
vmin = None,
vmax = None,
label = None,
margins = None,
hide_ticks = True
)
fig_nodes.set_linestyle(node_border_style[node])
# nodes labels
# ------------
if show_labels:
nodes = set(itertools.chain.from_iterable(node_subset.values()))
nodes_label = self.nodes_label | (nodes_label or {})
adj_x = self.__plot_label_adj__(node_label_adj_x, nodes_label)
adj_y = self.__plot_label_adj__(node_label_adj_y, nodes_label)
fc = self._plot_parse_aes_node('node_color', node_color, style_dict)
fontweight= self._plot_parse_aes_node('node_label_fontweight', node_label_fontweight, style_dict)
fontsize = self._plot_parse_aes_node('node_label_fontsize', node_label_fontsize, style_dict)
boxstyle = self._plot_parse_aes_node('node_label_box_style', node_label_box_style, style_dict)
boxmargin = self._plot_parse_aes_node('node_label_box_margin', node_label_box_margin, style_dict)
ec = self._plot_parse_aes_node('node_border_color', node_border_color, style_dict)
lw = self._plot_parse_aes_node('node_border_width', node_border_width, style_dict)
linestyle = self._plot_parse_aes_node('node_border_style', node_border_style, style_dict)
node_label_box = self._plot_parse_aes_node('node_label_box', node_label_box, style_dict)
for node in nodes:
label = nodes_label.get(node, node) if use_labels else node
role = self.nodes_info[node]['role']
x, y = nodes_position[node] if nodes_position and all(nodes_position[node]) else \
self.nodes_info[node]['position']
if node_label_box[node]:
bbox = {"boxstyle": f"{boxstyle[node]},pad={boxmargin[node]}",
"fc": fc[node],
"ec": ec[node],
"lw": lw[node],
"linestyle": linestyle[node],
"alpha": 1
}
else:
bbox = None
if fontweight[node]=='bold':
label = f"\\textbf{{{label}}}"
elif fontweight[node]=='italic':
label = f"\\textit{{{label}}}"
plt.text(x + adj_x[node],
y + adj_y[node],
label,
fontweight = 'normal',
fontsize = fontsize[node],
ha = 'center',
va = 'center',
bbox = bbox)
# edges and edges labels
# ----------------------
nodes = set(itertools.chain.from_iterable(node_subset.values()))
style = self._plot_parse_aes_edge("edge_style", edge_style, style_dict)
color = self._plot_parse_aes_edge("edge_color", edge_color, style_dict)
arc = self._plot_parse_aes_edge("edge_arc", edge_arc, style_dict)
width = self._plot_parse_aes_edge("edge_linewidth", edge_linewidth, style_dict)
arrow_head_size = self._plot_parse_aes_edge("edge_head_size", edge_head_size, style_dict)
arrow_head_style = self._plot_parse_aes_edge("edge_head_style", edge_head_style, style_dict)
edge_margin_head = self._plot_parse_aes_edge("edge_margin_head", edge_margin_head, style_dict)
edge_margin_tail = self._plot_parse_aes_edge("edge_margin_tail", edge_margin_tail, style_dict)
edge_label_alpha = self._plot_parse_aes_edge("edge_label_alpha", edge_label_alpha, style_dict)
edge_label_size = self._plot_parse_aes_edge("edge_label_size", edge_label_size, style_dict)
edge_label_color = self._plot_parse_aes_edge("edge_label_color", edge_label_color, style_dict)
edge_label_rotate = self._plot_parse_aes_edge("edge_label_rotate", edge_label_rotate, style_dict)
edge_label_position = self._plot_parse_aes_edge("edge_label_position", edge_label_position, style_dict)
edge_label_color_border = self._plot_parse_aes_edge("edge_label_color_border", edge_label_color_border, style_dict)
edge_label_color_background = self._plot_parse_aes_edge("edge_label_color_background", edge_label_color_background, style_dict)
edge_label_font_weight = {edge: 'normal' for edge in edge_label_color}
if estimates is not None:
edge_label_color = self.__plot_apply_estimate_sign_feature__(
edge_label_color,
estimate_label_sign,
edge_label_estimates_colors
)
edge_label_font_weight = self.__plot_apply_estimate_sign_feature__(
edge_label_font_weight,
estimate_label_sign,
edge_label_estimates_face
)
edge_label_alpha = self.__plot_apply_estimate_sig_alpha__(
edge_label_alpha,
estimate_label_pvalue,
edge_label_estimates_show_sig_alpha,
edge_label_estimates_sig_level
)
for edge_type in ['directed', 'bidirected', 'undirected']:
for edge in self.__getattribute__(edge_type):
if edge_type == 'directed':
u, v = tuple(edge)
elif edge_type=='bidirected':
u, v = edge[0]
elif edge_type=='undirected':
u, v = tuple(edge)
edge = frozenset(edge)
if edge_subset:
e = set(edge) if edge_type=='undirected' else edge
show_edge = self.edge_exist(e, edge_subset.get(edge_type, []))
else:
show_edge = True
if u in nodes and v in nodes and show_edge:
# edge
nx.draw_networkx_edges(
G_draw,
nodes_position,
edgelist = [(u, v)],
nodelist = [u, v],
node_size = [node_size[u], node_size[v]],
style = style[edge],
edge_color = color[edge],
connectionstyle = f"arc3,rad={arc[edge]}",
arrows = True,
arrowstyle = arrow_head_style[edge],
arrowsize = arrow_head_size[edge],
min_source_margin = edge_margin_tail[edge],
min_target_margin = edge_margin_head[edge],
width = width[edge],
ax=ax)
# edge label
edge_label = edge_label or self.edge_label
label = edge_label.get(edge, '')
rotate = edge_label_rotate if edge_label_rotate is not None else True # must keep "is not None" here
nx.draw_networkx_edge_labels(
G_draw,
pos = nodes_position,
edge_labels = {(u, v): label},
bbox = dict(facecolor=edge_label_color_background[edge],
edgecolor=edge_label_color_border[edge]),
alpha = edge_label_alpha[edge],
font_size = edge_label_size[edge],
font_color = edge_label_color[edge],
font_weight = edge_label_font_weight[edge],
rotate = edge_label_rotate[edge],
label_pos = edge_label_position[edge],
font_family = edge_label_font_family,
connectionstyle = f"arc3,rad={arc[edge]}",
ax = ax
)
# legend (aggreagate per role, not per node)
# ------
if legend_show:
keys = []
for role, nodes in node_subset.items():
if role not in legend_omit_cases:
# collect aes for all latent nodes
marker = []
color = []
markeredgecolor = []
markerfacecolor = []
linestyle = []
for i, node in enumerate(nodes):
linestyle += [node_border_style[node]]
marker += [''] if linestyle[i] in ['--', 'dotted', 'dashed', ':'] else ['o']
color += [node_border_color[node]]#['black'] if role == 'Latent' else ['white']
markeredgecolor += [node_border_color[node]]
markerfacecolor += [node_color[node]]
# add only unique aes to legend
for marker, color, markeredgecolor, markerfacecolor, linestyle in \
set(zip(marker, color, markeredgecolor, markerfacecolor, linestyle)):
keys += [
Line2D(
[0], [0],
marker=marker,
color = color,
label = role,
markersize = 10,
markeredgecolor=markeredgecolor,
markerfacecolor=markerfacecolor,
linestyle=linestyle
)]
if keys:
legend = plt.legend(handles = keys,
title = legend_title,
title_fontsize = legend_title_size,
alignment = legend_title_align,
# title_weight = legend_title_weight,
loc = legend_loc,
fontsize = legend_fontsize,
frameon = legend_frame,
**legend_kws
)
if legend_title_weight=='bold' and legend_title:
legend.set_title(title=f'\\textbf{{{legend_title}}}', prop={'weight': 'bold'})
# title
# -----
if title:
plt.title(label=title, loc=title_loc, **title_kws)
plt.axis("off")
plt.tight_layout()
if show_plot:
plt.show()
plt.rcParams["text.usetex"] = default_usetex
return plt, ax
def plot_paths(self, exposure=None, outcome=None, adj_set=None, directed=False,
show_full_dag = True,
use_labels=True,
title_fontsize = 10,
figsize=(16, 9),
path_color='black',
**plot_kws
):
"""
Plot individual paths between exposure and outcome nodes.
Parameters
----------
exposure : str or list[str] or None, optional
Exposure node(s) to anchor the paths. Defaults to the DAG exposure
role when omitted.
outcome : str or list[str] or None, optional
Outcome node(s) serving as path targets. Defaults to the DAG outcome
role when omitted.
adj_set : str or Sequence[str] or None, optional
Adjustment set used to assess path openness. Strings are promoted to
single-element lists.
directed : bool, optional
If ``True``, restrict to directed paths from exposure to outcome.
Defaults to ``False``.
show_full_dag : bool, optional
Draw the entire DAG in the background with muted styling before
highlighting each path. Defaults to ``True``.
use_labels : bool, optional
When ``True`` (default), prefer custom node labels over names.
title_fontsize : int, optional
Font size for subplot titles. Defaults to ``10``.
figsize : tuple[float, float], optional
Size of the grid of path plots in inches. Defaults to ``(16, 9)``.
path_color : str, optional
Color applied to highlighted path edges. Defaults to ``'black'``.
**plot_kws :
Additional keyword arguments forwarded to ``DAG.plot`` for both the
background DAG (when ``show_full_dag`` is ``True``) and each path.
Returns
-------
list[matplotlib.axes.Axes]
Axes objects for the generated subplots. The list is flattened even
when the grid contains a single axis.
Examples
--------
>>> G = DAG(graph="X -> Z -> Y")
>>> axes = G.plot_paths(exposure="X", outcome="Y", directed=True, show_full_dag=False)
>>> len(axes)
1
"""
if show_full_dag:
assert self.nodes_position, "Nodes position must be set when show_full_dag=True"
default_usetex = plt.rcParams["text.usetex"]
plt.rcParams["text.usetex"] = True
packages = ["amsmath", "amssymb", "siunitx", "bm", "wasysym", "marvosym"]
plt.rcParams['text.latex.preamble'] = rf"\usepackage{{{', '.join(packages)}}}"
adj_set = [adj_set] if isinstance(adj_set, str) else adj_set
paths = self.paths(exposure=exposure, outcome=outcome, adj_set=adj_set, directed=directed)
npaths = len(paths)
ncols = int(math.ceil(math.sqrt(npaths)))
nrows = int(math.ceil(npaths / ncols))
fig, axs = plt.subplots(nrows, ncols, figsize=figsize, tight_layout=True)
if ncols >1 or nrows>1:
axs=axs.flatten()
else:
axs = [axs]
[ax.axis('off') for ax in axs]
#
pos = self.nodes_position
roles = self.nodes_role
nodes_label = self.nodes_label
edge_label = self.edge_label
for i, (path, info) in enumerate(paths.items()):
ax = axs[i]
show_labels=True
if show_full_dag:
self.plot(ax=ax, edge_color ='lightgray', **plot_kws)
show_labels=False
# G2 = DAG(path, nodes_role=roles, nodes_position=pos, nodes_label=nodes_label)
G2 = self.__rebuild_graph__(path)
G2.plot(ax=ax, edge_linewidth=3, show_labels=show_labels,
edge_color=path_color, use_labels=use_labels, **plot_kws)
adj = info['adj_set']
if adj:
adj = [self.nodes_label.get(x, x) for x in adj] if use_labels else adj
adj = ', '.join(adj)
else:
adj = ""
title = rf"Path is \textbf{{{'open' if info['open'] else 'closed'}}}; Adjustment set: "+"\{"+adj+"\}"
ax.set_title(title, loc='left', fontsize=title_fontsize)
ax.axis('on')
plt.tight_layout()
plt.rcParams["text.usetex"] = default_usetex
return axs
def plot_equivalent_dags(self,
use_labels=True,
show_labels=True,
edge_difference_color='red',
title_fontsize = 10,
title_original_graph = 'Original Graph',
title_equivalent_graph = "Equivalent DAG",
show_footnote = True,
figsize=(16, 9),
max_per_figure = 9,
max_eq_dags= 27,
**plot_kws
):
"""
Visualize multiple DAGs in the Markov equivalence class.
Parameters
----------
use_labels : bool, optional
Prefer custom node labels when ``True`` (default).
show_labels : bool, optional
Display node labels on the plots. Defaults to ``True``.
edge_difference_color : str, optional
Color used to highlight edges that differ from the original graph
in each equivalent DAG. Defaults to ``'red'``.
title_fontsize : int, optional
Font size for subplot titles. Defaults to ``10``.
title_original_graph : str, optional
Title assigned to the baseline plot of the original DAG.
title_equivalent_graph : str, optional
Title applied to each equivalent DAG subplot.
show_footnote : bool, optional
Display a numbered footnote beneath each subplot when ``True``.
figsize : tuple[float, float], optional
Figure size in inches for each panel grid. Defaults to ``(16, 9)``.
max_per_figure : int, optional
Maximum number of panels per figure. Defaults to ``9``.
max_eq_dags : int, optional
Cap on the number of equivalent DAGs to display. Defaults to ``27``.
**plot_kws :
Additional keyword arguments forwarded to ``DAG.plot``.
Returns
-------
dict[int, list]
Mapping from figure index to ``[figure, axes_list]`` pairs. Returns
``None`` when no equivalent DAGs exist.
Examples
--------
>>> G = DAG(graph="X -> Z <- Y")
>>> figs = G.plot_equivalent_dags(show_footnote=False, max_eq_dags=4)
>>> isinstance(figs, dict)
True
"""
# collecting equivalent DAGs
eq_dags = self.equivalent_dags()
n_eq_dags = len(eq_dags)
if n_eq_dags == 0:
return None
if n_eq_dags > max_eq_dags:
print(f"\n**Note:**\n"+
f"---------\n"
f"Maximun number of equivalent DAGs to plot is set to {max_eq_dags}"+
f" by default, but there are {n_eq_dags} equivalent DAGs. Some equivalent DAGs"+
f" will be omitted. To change it, set 'max_eq_dags'.\n")
max_eq_dags = np.min([n_eq_dags, max_eq_dags])
figs = dict(self.__chunked_ranges__(max_eq_dags, max_per_figure))
print(f"Total of equivalent DAGs: {n_eq_dags}\n"+
f"Plotting {max_eq_dags} equivalent DAG(s)\n"
f"Generating {len(figs.keys())} figure(s) with a maximum of {max_per_figure} panels per figure\n")
figs_res = {}
nodes_subset = plot_kws.pop("node_subset", None)
legend_show = plot_kws.pop("legend_show", True)
for fig_number, panels in figs.items():
# figure
ncols = int(math.ceil(math.sqrt(max_per_figure)))
nrows = int(math.ceil(max_per_figure / ncols))
fig, axs = plt.subplots(nrows, ncols, figsize=figsize, tight_layout=True)
if ncols >1 or nrows>1:
axs=axs.flatten()
else:
axs = [axs]
[ax.axis('off') for ax in axs]
# panels
for panel, panel_number in enumerate(panels):
print(f"Creating plot {panel_number+1} of {n_eq_dags}...", end='')
ax = axs[panel]
eq_dag = eq_dags[panels[panel]]
panel_legend_show = legend_show and panel_number == 0
# baseline plot
eq_dag.plot(ax=ax,
node_subset = nodes_subset,
legend_show=panel_legend_show,
edge_linewidth=1,
show_labels=show_labels,
use_labels=use_labels,
title=title_equivalent_graph,
title_fontsize=title_fontsize,
**plot_kws)
# superimpose edges highlighing the differences
edges = self.edge_differences(eq_dag)['G2']
nodes = self.__collect_nodes_from_edges__(edges)
if nodes_subset is not None:
nodes = list(set(nodes).intersection(nodes_subset))
if nodes:
eq_dag.plot(ax=ax, edge_linewidth=3,
node_subset = nodes,
edge_subset = edges,
legend_show=False,
show_labels=show_labels,
edge_color=edge_difference_color,
use_labels=use_labels,
title=title_equivalent_graph,
title_fontsize=title_fontsize,
**plot_kws)
if show_footnote:
# footnote
xcoord=1
ycoord=1.07
yoffset=-.1
fn = f"Equivalent DAG: {panel_number+1} of {n_eq_dags}"
ax.annotate(fn, xy=(xcoord,yoffset), xytext=(xcoord,yoffset),
xycoords='axes fraction', size=11, ha='right',
style='italic', alpha=.6)
print('done!')
ax.axis('on')
plt.tight_layout()
figs_res[fig_number] = [fig, axs]
return figs_res
def plot_equivalence_class(self, *args, **kws):
"""
Plot the partially directed Markov equivalence class of the DAG.
Parameters
----------
*args :
Positional arguments forwarded to ``DAG.plot``.
**kws :
Keyword arguments forwarded to ``DAG.plot``.
Returns
-------
matplotlib.axes.Axes
Axis containing the rendered equivalence class.
Examples
--------
>>> G = DAG(graph="X -> Z <- Y")
>>> ax = G.plot_equivalence_class(show_plot=False)
>>> ax is not None
True
"""
self.equivalence_class().plot(*args, **kws)
def plot_identification(self,
content='default', # detailed, default
effect='total', #total, direct, or do, only if if_info=full
show_np = True,
show_linear = True,
show_do = True,
kws_graph={},
kws_identification={},
kws_detailed = None,
figsize = None,
ratio = None,
ncols = None,
nrows = None,
title_dag = None,
title_info = None,
txt_line_height=.55,
*args,
**kws
):
"""
Plot identification information alongside the DAG.
Parameters
----------
content : {'default', 'detailed'}, optional
Level of detail displayed in the identification summary. Defaults to
``'default'``.
effect : {'total', 'direct', 'do'}, optional
Effect type to highlight when ``content`` requires it. Defaults to
``'total'``.
show_np, show_linear, show_do : bool, optional
Toggle inclusion of non-parametric, linear, and do-calculus
strategies in the summary. All default to ``True``.
kws_graph : dict, optional
Keyword arguments forwarded to ``DAG.plot`` for the DAG panel.
kws_identification : dict, optional
Arguments passed to ``identification_analysis`` before plotting.
kws_detailed : dict or None, optional
Overrides for detailed identification output (e.g.,
``{'strategy': 'SoO', 'parameter': 'ACE'}``). Defaults to selecting
the first available parameter.
figsize : tuple[float, float] or None, optional
Figure size in inches. When ``None``, the identification plotting
routine chooses a default.
ratio : float or None, optional
Aspect ratio override for the combined plot.
ncols, nrows : int or None, optional
Layout configuration for identification panels.
title_dag : str or None, optional
Title displayed above the DAG subplot.
title_info : str or None, optional
Title for the identification summary panel.
txt_line_height : float, optional
Text line height used when ``figsize`` is not provided. Defaults to
``0.55``.
*args :
Additional positional arguments forwarded to the underlying plotting
routine.
**kws :
Extra keyword arguments forwarded to the underlying plotting routine.
Returns
-------
tuple
Result of ``self.__identification__.plot`` which includes figure and
axes handles.
Examples
--------
>>> G = DAG(graph="X -> Y")
>>> G.identification_analysis(exposure="X", outcome="Y", verbose=False)
>>> result = G.plot_identification(show_plot=False)
"""
roles = ['Exposure', 'Outcome', 'Latent', 'Observed',
'exposure', 'outcome', 'latent', 'observed']
for role in roles:
assert not kws_graph.get(role, None) and not kws_identification.get(role, None), (
f"Setting node role ({role}) not allowed in the plot kws. "+
f"To set the node role, create a new DAG or use set_node_role before plotting.")
if not self.__identification__ or kws_identification:
self.identification_analysis(**kws_identification, verbose=False)
# defaults for kws_detailed
kws_detailed = kws_detailed or {}
strategy = kws_detailed.get('strategy', 'SoO')
parameter = kws_detailed.get('parameter', None)
if not parameter:
parameter = next(iter(self.__identification__.identification[strategy]))
kws_detailed['strategy'] = strategy
kws_detailed['parameter'] = parameter
return self.__identification__.plot(G=self,
info=content,
effect=effect,
show_np = show_np,
show_linear = show_linear,
show_do = show_do,
figsize=figsize,
ratio=ratio,
ncols=ncols,
nrows=nrows,
kws_graph=kws_graph,
kws_detailed = kws_detailed,
txt_line_height=txt_line_height,
title_dag = title_dag,
title_info = title_info,
*args,
**kws
)
# building graph --------------------------------
def __build_graph__(self, graph):
# Always convert to dict first, and from dict to other formats
# dict -> list
# dict -> str
# str -> dict -> list
# list-> dict -> str
if isinstance(graph, str):
self.__graph_str_parse__(graph)
self.__graph_str2dict__()
self.__graph_dict2list__()
elif isinstance(graph, dict):
self.__graph_dict_parse__(graph)
self.__graph_dict2str__()
self.__graph_dict2list__()
elif isinstance(graph, list):
self.__graph_list_parse__(graph)
self.__graph_list2dict__()
self.__graph_dict2str__()
def __graph_list_parse__(self, graph):
for e in graph:
if e not in self.__graph_list__:
self.__graph_list__ += [e]
def __graph_dict_parse__(self, graph):
self.__graph_dict__ = {'directed':[], 'bidirected':[], 'undirected':[]}
for edge_type, edges in graph.items():
for edge in edges:
if edge not in self.__graph_dict__[edge_type]:
self.__graph_dict__[edge_type] += [edge]
def __graph_str_parse__(self, graph):
self.__graph_str_original__ = graph
edges_type = "|".join(self.__edges_str_allowed__)
# edges_type = '|'.join(sorted(map(re.escape, self.__edges_str_allowed__), key=len, reverse=True))
self.__graph_str_parsed__ = []
regex = re.compile(rf"(\w+|\{{[^}}]*\}})\s*({edges_type})\s*(\w+|\{{[^}}]*\}})")
# remove comments
graph = "\n".join(line for line in re.sub(r"#.*", "", graph).splitlines() if line.strip())
graph = self.__graph_str_parse_inline_paths__(graph)
for ln in graph.strip().splitlines():
ln = ln.strip()
# collect if not a comment
if not bool(re.search(pattern="^ ?#", string=ln)):
m = regex.match(ln)
if m:
nodes1, edge, nodes2 = m.groups()
nodes1 = re.sub(pattern='\\{|\\}', repl='', string=nodes1)
nodes1 = re.split(r"[,\s]+", nodes1.strip())
nodes2 = re.sub(pattern='\\{|\\}', repl='', string=nodes2)
nodes2 = re.split(r"[,\s]+", nodes2.strip())
for n1, n2 in itertools.product(nodes1, nodes2):
self.__graph_str_parsed__.append(f"{n1} {edge} {n2}")
else:
raise ValueError(f"Unrecognized line format: '{ln}'")
self.__graph_str_parsed__ = "\n".join(self.__graph_str_parsed__)
return None
def __graph_str_parse_inline_paths__(self, dag):
# Split the path string by spaces to separate nodes and arrows
lines = dag.split("\n")
edges_type = '|'.join(sorted(map(re.escape, self.__edges_str_allowed__), key=len, reverse=True))
res = []
for path in lines:
delimiter_pattern = re.compile(rf'({edges_type})')
unique_edges = set()
# Split the path by the arrow delimiters
components_raw = delimiter_pattern.split(path)
# Clean the list: remove empty strings and strip whitespace from each part
components = [c.strip() for c in components_raw if c and c.strip()]
# Iterate through the components, taking 3 at a time to form an edge
for i in range(0, len(components) - 1, 2):
node1 = components[i]
arrow = components[i+1]
node2 = components[i+2]
# Re-format the edge with standard spacing for consistent output
edge = f"{node1} {arrow} {node2}"
unique_edges.add(edge)
res += ["\n".join(unique_edges)]
res = "\n".join(res)
res = res.replace("<- >", "<->")
return res
def __graph_str2dict__(self):
# Parse DAG string to properties of the graph: nodes, directed,
# bidirected, and undirected edges.
DAG = self.__graph_str_parsed__
directed, undirected, bidirected = [], [], []
# One regex to handle all edge types
pattern = re.compile(r"^\s*(\w+)\s*(->|<-|<->|--)\s*(\w+)\s*$")
lines = DAG.strip().splitlines()
for line in lines:
line = line.strip()
if not line or line.startswith("#"):
continue # skip empty/comment lines
m = pattern.match(line)
if not m:
raise ValueError(f"\nUnrecognized format: '{line}'")
lhs, op, rhs = m.groups()
if op == "->":
a, b = lhs, rhs
directed.append((a, b))
elif op == "<-":
a, b = rhs, lhs # normalize as parent=a -> child=b
directed.append((a, b))
elif op == "<->":
a, b = lhs, rhs
bidirected.append( ((a, b), (b, a)) )
elif op == "--":
a, b = lhs, rhs
undirected.append({a, b})
# single place to update the node set
self.nodes.update({a, b})
# eliminate duplicates
directed = list(set(directed))
bidirected = list(set(bidirected))
undirected = list(set([tuple(g) for g in undirected]))
undirected = [set(g) for g in undirected]
self.__graph_dict__ = {"directed" : directed,
'bidirected': bidirected,
'undirected': undirected}
def __graph_list2dict__(self):
self.__graph_dict__ = {'directed':[], 'bidirected':[], 'undirected':[]}
for edge in self.__graph_list__:
edge_type = self.__edge_type__(edge)
self.__graph_dict__[edge_type] += [edge]
def __graph_dict2list__(self):
self.__graph_list__ = []
for type, edges in self.__graph_dict__.items():
self.__graph_list__ += [edges]
# flatten
self.__graph_list__ = list(itertools.chain.from_iterable(self.__graph_list__))
def __graph_dict2str__(self):
self.__graph_str_parsed__ = ''
for type, edges in self.__graph_dict__.items():
for nodes in edges:
if type=='directed':
edge = '->'
if type=='bidirected':
edge = '<->'
nodes = nodes[0]
if type=='undirected':
edge = '--'
nodes = list(nodes)
self.__graph_str_parsed__ += f"{nodes[0]} {edge} {nodes[1]}\n"
self.__graph_str_original__ = self.__graph_str_parsed__
# collect info
def __collect_info__(self, nodes_role, nodes_position, nodes_label):
# collect info (keep order)
self.__collect_nodes__()
self.__collect_nodes_parents__()
self.__collect_nodes_role__(nodes_role)
self.__collect_nodes_position__(nodes_position)
self.__collect_nodes_label__(nodes_label)
#
self.nodes_info = {node:{} for node in self.nodes}
self.__collect_info_nodes_role__()
self.__collect_info_nodes_position__()
self.__collect_info_nodes_label__()
#
self.__collect_edges_properties__()
def __collect_nodes__(self):
nodes = set()
for edge_type, edges in self.__graph_dict__.items():
for edge in edges:
for node in edge:
if edge_type=='bidirected':
node = node[0]
nodes = nodes.union([node])
self.nodes = nodes
def __collect_nodes_parents__(self):
self.nodes_parents = defaultdict(set) # child -> {parents}
for n1, n2 in self.__graph_dict__['directed']:
self.nodes_parents[n2].update([n1])
self.nodes_parents = dict(self.nodes_parents)
def __collect_nodes_label__(self, nodes_label):
nodes_label = nodes_label or {}
for node in self.nodes:
self.nodes_label[node] = nodes_label.get(node, None) or node
def __collect_nodes_position__(self, nodes_position):
if nodes_position:
self.nodes_position = {}
for node, pos in nodes_position.items():
if node in self.nodes:
self.nodes_position[node] = pos
def __collect_nodes_role__(self, nodes_role):
nodes_role = nodes_role or {}
self.nodes_role['Observed'] = [] # keep this here
nodes_with_role_already_set = []
for role, node in nodes_role.items() :
if role=='Outcome':
if isinstance(node, list) and len(node)==1:
node = node[0]
assert isinstance(node, str), "Check nodes_role. Node 'Outcome' must be a string or a 1-element list."
else:
assert isinstance(node, str) or isinstance(node, list), \
"Check nodes_role. Nodes 'Exposure' and 'Latent' must be strings or lists"
node = node if isinstance(node, list) else [node]
self.nodes_role[role] = [n for n in node if n in self.nodes]
nodes_with_role_already_set += node
# set observed as default if role of node is not provided
for node in self.nodes:
if node not in nodes_with_role_already_set:
self.nodes_role['Observed'] += [node]
self.exposure = self.nodes_role.get('Exposure', None)
self.outcome = self.nodes_role.get('Outcome', None)
self.latent = self.nodes_role.get('Latent', None)
self.observed = self.nodes_role.get('Observed', None)
def __collect_info_nodes_role__(self):
res = {}
for role, nodes in self.nodes_role.items():
for node in nodes:
self.nodes_info[node]['role'] = role
def __collect_info_nodes_position__(self):
res = {}
for node, position in self.nodes_position.items():
self.nodes_info[node]['position'] = position
def __collect_info_nodes_label__(self):
res = {}
for node, label in self.nodes_label.items():
self.nodes_info[node]['label'] = label
def __collect_edges_properties__(self):
self.directed = self.__graph_dict__['directed']
self.bidirected = self.__graph_dict__['bidirected']
self.undirected = self.__graph_dict__['undirected']
# R dagitty
def __create_dagitty__(self):
# # Convert to dagitty string: "dag { A -> B; B -> C; ... }"
# edges = [f"{u} -> {v}" for u, v in self.G.edges()]
# edges = '; '.join(edges)
roles = ''
for role, nodes in self.nodes_role.items():
for node in nodes:
roles += f"{node} [{role.lower()}]\n"
# Load dagitty and pass the DAG string
dagitty_str = f"dag {{ {self.__graph_str_parsed__} \n {roles} }}"
self.__dagitty__ = dagitty.dagitty(dagitty_str)
# R dagitty
def __dagitty2inputs__(self, dag_dagitty):
dag_str = ''
dag_df = convert().rtibble2tp(dagitty.edges(dag_dagitty))
for a, b, e, *_ in dag_df.to_polars().iter_rows():
dag_str += f"{a} {e} {b}\n"
roles = {"Exposure": list(dagitty.exposures(dag_dagitty)),
'Outcome' : list(dagitty.outcomes(dag_dagitty)),
"Latent" : list(dagitty.latents(dag_dagitty))}
return dag_str, roles
# -------------------------------------------------
def __rebuild_graph__(self, graph):
res = DAG(graph,
nodes_role = self.nodes_role,
nodes_position = self.nodes_position,
nodes_label = self.nodes_label,
edge_label = self.edge_label
)
return res
def __repr__(self):
self.__print_graph__()
return ''
def __str__(self):
self.__repr__()
return ''
def __print_graph__(self):
out = 'Graph:\n'
d = [f"{n1} -> {n2}" for n1, n2 in self.directed]
out += '\n'.join(d) if len(d)>0 else ''
b = [f"{n1[0]} <-> {n2[0]}" for n1, n2 in self.bidirected]
out += '\n' + '\n'.join(b) if len(b)>0 else ''
u = [f"{n1} -- {n2}" for n1, n2 in self.undirected]
out += '\n' +'\n'.join(u) if len(u)>0 else ''
roles = [f"{role}: {', '.join(nodes)}" for role, nodes in self.nodes_role.items()]
out += "\n"+"\n".join(roles) if len(roles)>0 else ''
print(out)
return out
def __collect_nodes_from_edges__(self, edges_dict):
nodes = []
for edge_type, edges in edges_dict.items():
if edge_type!='bidirected':
nodes += list(set(itertools.chain.from_iterable(edges)))
else:
nodes += list(set(itertools.chain.from_iterable(itertools.chain.from_iterable(edges))))
return nodes
def __chunked_ranges__(self, limit, n):
# Split [0..limit] into chunks.
# Each chunk has n elements, except:
# - the last one may have fewer if not divisible, OR
# - the last one may be larger if needed to include 'limit'.
start = 0
idx = 0
limit -=1
while start <= limit:
end = start + n - 1
if end >= limit: # last chunk, go all the way to limit
yield idx, list(range(start, limit + 1))
break
else:
yield idx, list(range(start, end + 1))
start = end + 1
idx += 1
def __edge_frozen_format__(self, edge):
# Convert an edge into a canonical, hashable form.
# - directed: ('A','B')
# - undirected: frozenset({'A','B'})
# - bidirected: frozenset({('A','B'),('B','A')})
# undirected
if isinstance(edge, (set, frozenset)):
return frozenset(edge)
# bidirected
if (isinstance(edge, tuple)
and len(edge) == 2
and all(isinstance(e, tuple) and len(e) == 2 for e in edge)):
return frozenset([tuple(edge[0]), tuple(edge[1])])
# directed
if (isinstance(edge, tuple)
and len(edge) == 2
and all(isinstance(x, str) for x in edge)):
return tuple(edge)
raise ValueError(f"Unrecognized edge format: {edge}")
def __edge_type__(self, edge):
# """
# Classify an edge as 'directed', 'bidirected', or 'undirected'.
# """
# Undirected: set/frozenset of 2 nodes
if isinstance(edge, (set, frozenset)):
if all(isinstance(x, str) for x in edge) and len(edge) == 2:
return "undirected"
# Bidirected: tuple of two directed edges
if (isinstance(edge, tuple)
and len(edge) == 2
and all(isinstance(e, tuple) and len(e) == 2 for e in edge)
and all(isinstance(x, str) for e in edge for x in e)):
return "bidirected"
# Directed: tuple of two nodes
if (isinstance(edge, tuple)
and len(edge) == 2
and all(isinstance(x, str) for x in edge)):
return "directed"
raise ValueError(f"Unrecognized edge format: {edge}")
# comparing SCM
def edge_differences(self, G2):
"""
Compare edge sets between two DAGs by edge type.
Parameters
----------
G2 : DAG
Graph to compare with the current instance.
Returns
-------
dict[str, dict[str, list]]
Dictionary with keys ``'G1'`` and ``'G2'``, each mapping to a
dictionary keyed by edge type (``'directed'``, ``'undirected'``,
``'bidirected'``) listing edges present in one graph but absent in
the other.
Examples
--------
>>> G1 = DAG(graph="X -> Y")
>>> G2 = DAG(graph="X <- Y")
>>> diff = G1.edge_differences(G2)
>>> diff["G1"]["directed"]
[('X', 'Y')]
"""
res1 = self.__edge_differences__(G2)
res2 = G2.__edge_differences__(self)
return {"G1":res1, "G2":res2}
def __edge_differences__(self, G2):
res1 = {}
edge_types = ['directed', 'undirected', 'bidirected']
for edge_type in edge_types:
res1[edge_type] = []
edges_list1 = self.__getattribute__(edge_type)
edges_list2 = G2.__getattribute__(edge_type)
for edge in edges_list1:
if edge_type=='bidirected':
if edge not in edges_list2 and (edge[1], edge[0]) not in edges_list2:
res1[edge_type] += [edge]
else:
if edge not in G2.__getattribute__(edge_type):
res1[edge_type] += [edge]
return res1
# -------------------------------------------------
# ancillary
def __plot_create_nx__(self):
G = nx.MultiDiGraph() # allows multiple edges & types
# Directed edges
for u, v in self.directed:
G.add_edge(u, v, type="directed")
# Bidirected edges: add both directions
for (u1, v1), (u2, v2) in self.bidirected:
G.add_edge(u1, v1, type="bidirected")
G.add_edge(u2, v2, type="bidirected")
# Undirected edges: add both directions
for uv in self.undirected:
u, v = tuple(uv)
G.add_edge(u, v, type="undirected")
G.add_edge(v, u, type="undirected")
return G
def __plot_nodes_subset__(self, node_subset, node_latent_show):
node_subset = node_subset or self.nodes
nodes_to_plot = {}
for role, nodes in self.nodes_role.items():
if role=='Latent' and not node_latent_show:
continue
else:
nodes_to_plot[role] = set([node for node in nodes if node in node_subset])
return nodes_to_plot
def __plot_nodes_positions__(self, G_draw, nodes_position):
nodes_position = nodes_position or self.nodes_position
if not nodes_position:
try:
from networkx.drawing.nx_pydot import graphviz_layout
nodes_position = graphviz_layout(G_draw, prog="dot")
except ImportError:
nodes_position = nx.spring_layout(G_draw)
return nodes_position
def __plot_label_adj__(self, node_label_adj, nodes_label):
if isinstance(node_label_adj, dict):
adj = {node:node_label_adj.get(node, 0)
for node in self.get_nodes(exclude_latent=False)}
elif isinstance(node_label_adj, (float, int)):
adj = {node:node_label_adj
for node in self.get_nodes(exclude_latent=False)}
# same for if labels are used
for node, label in nodes_label.items():
adj[label] = adj[node]
return adj
def __plot_collect_labels_estimate__(self, estimates, show_sig=True,
show_se=False, show_ci=False,
show_ci_round=4):
tab = estimates.summary(output='tibble', style='full')
tab = tab.to_pandas() if hasattr(tab, "to_pandas") else tab
digits = 4
labels = {}
pvalues = {}
signs = {}
for row in tab.to_dict("records"):
edge = self.__plot_estimate_row_edge__(row)
if edge is None:
continue
estimate = self.__plot_as_float__(row.get('estimate'))
estimate_label = self.__plot_format_number__(estimate, digits)
if show_sig:
estimate_label = f"{estimate_label}{self.__plot_as_text__(row.get('sig'))}"
if show_ci:
lo = self.__plot_format_number__(self.__plot_as_float__(row.get('lo')),
show_ci_round)
hi = self.__plot_format_number__(self.__plot_as_float__(row.get('hi')),
show_ci_round)
estimate_label = f"{estimate_label}\n({lo}, {hi})"
labels[edge] = estimate_label
pvalue = self.__plot_as_float__(row.get('pvalue'))
if pvalue is not None:
pvalues[edge] = pvalue
if estimate is not None:
signs[edge] = 'negative' if estimate < 0 else 'positive'
return labels, pvalues, signs
def __plot_estimate_row_edge__(self, row):
term = str(row.get('term', '')).strip()
if not term:
return None
if '~~' in term:
left, right = [v.strip() for v in term.split('~~', 1)]
edge = ((left, right), (right, left))
edge_reverse = ((right, left), (left, right))
if edge in self.bidirected:
return edge
return edge_reverse if edge_reverse in self.bidirected else None
if '~' in term:
to_node, from_node = [v.strip() for v in term.split('~', 1)]
edge = (from_node, to_node)
return edge if edge in self.directed else None
return None
def __plot_as_float__(self, value):
try:
value = float(value)
except (TypeError, ValueError):
return None
return None if math.isnan(value) else value
def __plot_format_number__(self, value, digits):
if value is None:
return ''
return f"{round(value, digits):g}"
def __plot_as_text__(self, value):
if value is None:
return ''
try:
if math.isnan(value):
return ''
except TypeError:
pass
return str(value).strip()
def __plot_apply_estimate_sign_feature__(self, base, signs, feature):
if feature is None:
return base
res = dict(base)
for edge, sign in signs.items():
if edge in res:
res[edge] = feature.get(sign, res[edge])
return res
def __plot_apply_estimate_sig_alpha__(self, base, pvalues, alpha, sig_level):
if alpha is None:
return base
res = dict(base)
for edge, pvalue in pvalues.items():
if edge in res:
key = 'Yes' if pvalue <= sig_level else 'No'
res[edge] = alpha.get(key, res[edge])
return res
def __plot_collect_aes__(self, role, aes_name, default):
res = None
if aes_name is not None:
if isinstance(aes_name, dict):
res = aes_name.get(role, None)
else:
res = aes_name
if not res:
res = default
return res
def __plot_edge_margin__(self, edge_margin, default=20):
edge_margin = edge_margin or {}
edges = self.directed + self.bidirected
if isinstance(edge_margin, (float, int)):
edge_margin = {e:edge_margin for e in edges}
edge_margin = {e:edge_margin.get(e, default) for e in edges}
return edge_margin
def __plot_edge_label_feature__(self, feature, edge, value, default=None,
alpha_level=0.05, label=None, edge_label_pvalue=None):
res = value.get(edge, default) if isinstance(value, dict) else (value or default)
# default color: red for negative, black for positive
if feature=='color' and not res:
try:
label = float(label)
res = 'red' if label < 0 else 'black'
except (TypeError, ValueError) as e:
# default
res = 'black'
# default alpha: full for significant, faded otherwise
if feature=='alpha' and not res and edge_label_pvalue:
try:
res = 1 if edge_label_pvalue.get(edge, 0) <= alpha_level else 0.2
except (TypeError, ValueError) as e:
# default
res = 1
return res
# def _plot_parse_aes_edge(self, aes_name, aes_to, defaults):
# # """
# # Parse arbitrary `aes_to` specification and return a dict
# # {
# # "directed": {edge: color, ...},
# # "bidirected": {edge: color, ...},
# # "undirected": {edge: color, ...},
# # }
# # where any unspecified edge gets its type-specific default color.
# # """
# # Bundle edges by type
# edges_by_type = {
# "directed": self.directed,
# "bidirected": self.bidirected,
# "undirected": {frozenset(s) for s in self.undirected}
# }
# # Initialize result with defaults
# result = {}
# for etype, edges in edges_by_type.items():
# default = defaults.get(etype)
# result[etype] = {e: default for e in edges}
# # If no customization or a single scalar: use it for all edges
# if aes_to is None:
# return result
# if not isinstance(aes_to, Mapping):
# # scalar (e.g., 'red'): apply to all edges across all types
# for etype, edges in result.items():
# for e in edges:
# result[etype][e] = aes_to
# return result
# # Build a lookup: edge -> edge_type
# edge_type_by_edge = {}
# for etype, edges in edges_by_type.items():
# for e in edges:
# edge_type_by_edge[e] = etype
# # Split the user spec into:
# # - type-level overrides: {'directed': 'green', ...}
# # - edge-level overrides: {(u, v): 'blue', frozenset(...): 'red', ...}
# type_level_spec = {}
# edge_level_spec = {}
# for key, val in aes_to.items():
# # Optional: support nested dict: {'directed': {edge1: 'red', ...}}
# if isinstance(key, str) and key in edges_by_type:
# # If the value is a mapping, treat it as edge-level for that type.
# if isinstance(val, Mapping):
# for e, c in val.items():
# edge_level_spec[e] = c
# else:
# type_level_spec[key] = val
# else:
# edge_level_spec[key] = val
# # Apply type-level defaults first
# for etype, color in type_level_spec.items():
# for e in edges_by_type[etype]:
# result[etype][e] = color
# # Apply per-edge overrides next (take precedence over type-level)
# for edge_key, color in edge_level_spec.items():
# # Direct lookup
# if edge_key in edge_type_by_edge:
# etype = edge_type_by_edge[edge_key]
# result[etype][edge_key] = color
# continue
# # If we get here, we didn't recognize the edge. You can either:
# # - raise an error, or
# # - silently ignore. I’ll raise to catch mistakes.
# raise ValueError(f"Unknown edge key in aes_to: {edge_key!r}")
# return result
def _plot_parse_aes_edge(self,
aes_name: str,
aes_to: Union[Any, Mapping[Any, Any], None],
style_default: Mapping[str, Any]):
# """
# Parse one edge aesthetic (given by `aes_name`) using STYLE_DEFAULT
# and an arbitrary user `aes_to`.
# Parameters
# ----------
# aes_name : str
# Name of the aesthetic in STYLE_DEFAULT["edges"],
# e.g. "edge_head_size", "edge_color", "edge_style", ...
# aes_to : scalar, dict, or None
# Arbitrary user specification for this aesthetic (same rules as
# _plot_parse_aes_edge_anc).
# style_default : mapping
# Typically your STYLE_DEFAULT.
# Returns
# -------
# Dict[edge, value]
# Flat mapping from edge object to that aesthetic value.
# """
edges_defaults = style_default["edges"][aes_name]
# edges_defaults is e.g. STYLE_DEFAULT["edges"]["edge_head_size"]
# == {"directed": 20, "bidirected": 20, "undirected": 0}
res = self._plot_parse_aes_edge_anc(directed=self.directed,
bidirected=self.bidirected,
undirected=self.undirected,
spec=aes_to,
defaults=edges_defaults)
return res
def _plot_parse_aes_edge_anc(self,
directed, bidirected, undirected,
spec: Union[Any, Mapping[Any, Any], None],
defaults: Mapping[str, Any],
):
# """
# Low-level helper: parse a *single* edge aesthetic.
# Parameters
# ----------
# directed : iterable of (u, v)
# bidirected : iterable of ((u, v), (v, u))
# undirected : iterable of sets/frozensets {u, v}
# spec : scalar, dict, or None
# - scalar -> apply to all edges
# - None -> use defaults by type
# - dict -> keys can be:
# * 'directed', 'bidirected', 'undirected' (case-insensitive)
# * actual edges:
# - ('D', 'Y') for directed
# - (('D', 'Y'), ('Y', 'D')) for bidirected
# - {'M1', 'M2'} or frozenset({'M1', 'M2'}) for undirected
# defaults : mapping
# e.g. STYLE_DEFAULT["edges"]["edge_head_size"], i.e.
# {
# "directed": 20,
# "bidirected": 20,
# "undirected": 0,
# }
# Returns
# -------
# Dict[edge, value]
# Flat mapping from *edge object* to the aesthetic value.
# Undirected edges use frozenset({u, v}) as key.
# """
# Normalize containers
directed_edges: List[DirectedEdge] = list(directed)
bidirected_edges: List[BidirectedEdge] = list(bidirected)
undirected_edges: List[frozenset] = [frozenset(e) for e in undirected]
# --- Case 1: scalar spec (apply to all edges) --------------------------
if spec is not None and not isinstance(spec, Mapping):
value = spec
result: Dict[Hashable, Any] = {}
for e in directed_edges:
result[e] = value
for e in bidirected_edges:
result[e] = value
for e in undirected_edges:
result[e] = value
return result
# --- Case 2: None -> use defaults only ---------------------------------
if spec is None:
d_default = defaults["directed"]
b_default = defaults["bidirected"]
u_default = defaults["undirected"]
result: Dict[Hashable, Any] = {}
for e in directed_edges:
result[e] = d_default
for e in bidirected_edges:
result[e] = b_default
for e in undirected_edges:
result[e] = u_default
return result
# --- Case 3: dict spec with type-level & edge-level overrides ----------
spec_dict: Mapping[Any, Any] = spec
known_kinds = {"directed", "bidirected", "undirected"}
# Type-level overrides (case-insensitive)
kind_overrides: Dict[str, Any] = {}
for k, v in spec_dict.items():
if isinstance(k, str):
kl = k.lower()
if kl in known_kinds:
kind_overrides[kl] = v
# Precompute sets for membership checks
directed_set = set(directed_edges)
bidirected_set = set(bidirected_edges)
undirected_set = set(undirected_edges)
# Per-edge overrides
directed_overrides: Dict[DirectedEdge, Any] = {}
bidirected_overrides: Dict[BidirectedEdge, Any] = {}
undirected_overrides: Dict[frozenset, Any] = {}
for k, v in spec_dict.items():
# skip kind keys already handled
if isinstance(k, str) and k.lower() in known_kinds:
continue
# directed edge override: ('u', 'v')
if isinstance(k, tuple) and len(k) == 2 and all(
isinstance(x, str) for x in k
):
if k in directed_set:
directed_overrides[k] = v
continue
# bidirected edge override: ((u,v), (v,u))
if (
isinstance(k, tuple)
and len(k) == 2
and all(isinstance(x, tuple) and len(x) == 2 for x in k)
):
if k in bidirected_set:
bidirected_overrides[k] = v
continue
# undirected edge override: {'u','v'} / frozenset({'u','v'})
if isinstance(k, (set, frozenset)):
fk = frozenset(k)
if fk in undirected_set:
undirected_overrides[fk] = v
continue
d_default = defaults["directed"]
b_default = defaults["bidirected"]
u_default = defaults["undirected"]
result: Dict[Hashable, Any] = {}
# Build final values with precedence: default -> kind -> per-edge
for e in directed_edges:
val = d_default
if "directed" in kind_overrides:
val = kind_overrides["directed"]
if e in directed_overrides:
val = directed_overrides[e]
result[e] = val
for e in bidirected_edges:
val = b_default
if "bidirected" in kind_overrides:
val = kind_overrides["bidirected"]
if e in bidirected_overrides:
val = bidirected_overrides[e]
result[e] = val
for e in undirected_edges:
val = u_default
if "undirected" in kind_overrides:
val = kind_overrides["undirected"]
if e in undirected_overrides:
val = undirected_overrides[e]
result[e] = val
return result
def _plot_parse_aes_node(self,
aes_name,
aes_to: Union[str, Dict[Any, str], None],
defaults: Dict[str, Dict[str, Any]]):
# """
# Parse arbitrary node aesthetic specifications (e.g., aes_to)
# and return a dict mapping each node to its final aesthetic value.
# Parameters
# ----------
# aes_to : str or dict or None
# Arbitrary user input:
# - str → apply to all nodes
# - dict → may contain:
# {node_name: color, node_type: color}
# defaults : dict
# Default aesthetics by node type, e.g.
# {
# "Exposure": {"aes_to": "lightgray", ...},
# "Observed": {"aes_to": "white", ...},
# }
# Returns
# -------
# dict: {node_name: color}
# """
defaults = defaults['nodes']
result = {}
nodes = self.nodes
node_roles = {n:info['role'] for n, info in self.nodes_info.items()}
# 1. Case: global color
if isinstance(aes_to, str | float | int):
return {node: aes_to for node in nodes}
# 2. Case: None → all defaults
if aes_to is None:
return {
node: defaults.get(node_roles[node], defaults['Observed'])[aes_name]
for node in nodes
}
# 3. Case: dict with type-level and node-level assignments
if isinstance(aes_to, dict):
# Normalize type keys (case-insensitive)
type_map = {k.lower(): v for k, v in aes_to.items()
if isinstance(k, str) and k.lower() in {t.lower() for t in self.nodes_role}}
# Node-specific overrides
node_map = {k: v for k, v in aes_to.items()
if k in nodes}
for node in nodes:
node_type = node_roles[node]
type_key = node_type.lower()
if node in node_map:
# highest priority
result[node] = node_map[node]
elif type_key in type_map:
# type-level override
result[node] = type_map[type_key]
else:
# default for node type
result[node] = defaults.get(node_type, defaults['Observed'])[aes_name]
return result
raise TypeError("aes_to must be either a string, dict, number, or None.")