Signature/Parameters
class estimate
def __init__(self, G, formula = None, data = None, model = 'auto', family = 'auto', se_cluster = None, se = None, model_kws = {}, weights = 1, *args, **kws)
Structural Equation Model (SCM) estimation of Graphical Causal Models (GCM).
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
G
|
DAG
|
Causal graph describing relationships among observed and latent
variables created by |
required |
model
|
Models for the functions of the structural causal model.
|
'auto'
|
|
formula
|
str or None
|
Formula for the functional form of the SCM. The formula depends on the
model used and defined by the argument
|
None
|
data
|
DataFrame - like
|
Observational dataset containing all variables referenced by the DAG or formula. |
None
|
family
|
str
|
Outcome distribution family. Defaults to |
'auto'
|
se_cluster
|
str
|
Name of the variable to cluster the std. errors. |
None
|
se
|
str or None
|
Options available depend on the |
None
|
model_kws
|
dict
|
Additional keyword arguments for the model defined in |
{}
|
weights
|
str or array - like
|
Observation weights passed through to the estimator. Defaults to
|
1
|
*args
|
Additional positional arguments forwarded to the underlying estimator. |
()
|
|
**kws
|
Additional keyword arguments forwarded to the underlying estimator. |
{}
|
Notes
For documentation of model-specific arguments, see:
- LSEM: ‘
causalinf.models.lsem‘ - NPSEM-IE-BART: ‘
causalinf.models.bart‘ - NPSEM-IE-GAM: ‘
causalinf.models.gam‘
Attributes:
| Name | Type | Description |
|---|---|---|
G |
DAG
|
Original DAG used in the estimation. |
formula |
str
|
SEM specification employed during fitting. |
fit |
object
|
Raw estimator output (e.g., lavaan fit object) when available. |
est |
dict
|
Summary bundle returned by the selected estimator, including parameter tables, fit statistics, and option metadata. |
Examples:
>>> dag = gcm.DAG("X -> Y")
>>> data = tp.tibble({'X': [0, 1, 0], 'Y': [1.0, 2.5, 1.2]})
>>> est = estimate(G=dag, data=data, silent=True)
>>> est.est['fit']['N_obs']
3
Source code in causalinf/scm.py
10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 | |
Examples
Estimate LSEM
Take this GCM example:
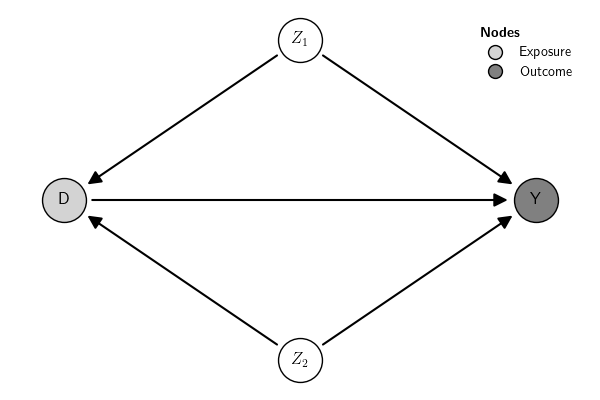
Simulate a data from a LSEM based on that DAG:
shape: (5, 4)
┌───────────────────────────────┐
│ Z1 Z2 D Y │
│ f64 f64 f64 f64 │
╞═══════════════════════════════╡
│ 1.33 1.51 -2.58 0.50 │
│ 0.72 -0.14 -0.42 -1.39 │
│ -1.55 -0.14 1.08 -0.59 │
│ -0.01 1.18 -0.90 -0.47 │
│ 0.62 1.18 0.22 0.07 │
└───────────────────────────────┘
Estimat the model:
Estimating LSEM...done!
================================================================================
Model: Model 1
Identification: SCM
Outcome: Y
Exposure: D
Formula:
# LSEM:
D ~ (beta_0D)*1 + (beta_Z1.D)*Z1 + (beta_Z2.D)*Z2
Y ~ (beta_0Y)*1 + (beta_D.Y)*D + (beta_Z1.Y)*Z1 + (beta_Z2.Y)*Z2
# Direct effect:
Direct_effect := (beta_D.Y)
# Total effect:
Total_effect := Direct_effect
Summary:
--------
term label estimate sig se lo hi statistic pvalue
D ~ 1 beta_0D 0.3129 *** 0.0312 0.2518 0.374 10.0358 0.0
D ~ Z1 beta_Z1.D -0.8867 *** 0.0333 -0.952 -0.8214 -26.6224 0.0
D ~ Z2 beta_Z2.D -0.9231 *** 0.0314 -0.9847 -0.8616 -29.3942 0.0
Y ~ 1 beta_0Y -0.2967 *** 0.0333 -0.3619 -0.2315 -8.9172 0.0
Y ~ D beta_D.Y 0.0179 0.0322 -0.0451 0.081 0.5571 0.5775
Y ~ Z1 beta_Z1.Y -0.0581 0.0443 -0.1449 0.0287 -1.312 0.1895
Y ~ Z2 beta_Z2.Y 0.1846 *** 0.0436 0.0991 0.2701 4.2314 0.0
D ~~ D 0.9715 *** 0.0434 0.8863 1.0566 22.3607 0.0
Y ~~ Y 1.0054 *** 0.045 0.9173 1.0935 22.3607 0.0
Z1 ~~ Z1 0.8798 0.0 0.8798 0.8798 -- --
Z1 ~~ Z2 0.0632 0.0 0.0632 0.0632 -- --
Z2 ~~ Z2 0.9896 0.0 0.9896 0.9896 -- --
Z1 ~ 1 -0.0146 0.0 -0.0146 -0.0146 -- --
Z2 ~ 1 -0.0111 0.0 -0.0111 -0.0111 -- --
Direct_effect := (be Direct_effect 0.0179 0.0322 -0.0451 0.081 0.5571 0.5775
Total_effect := Dire Total_effect 0.0179 0.0322 -0.0451 0.081 0.5571 0.5775
Model -- (footnote) -- -- -- -- -- --
Outcome type -- (footnote) -- -- -- -- -- --
Estimator -- ML -- -- -- -- -- --
Std.Error -- classic -- -- -- -- -- --
N.obs -- 1000 -- -- -- -- -- --
RMSE -- 0.0 -- -- -- -- -- --
AIC -- 5670.18 -- -- -- -- -- --
BIC -- 5714.35 -- -- -- -- -- --
DF (model) -- 0 -- -- -- -- -- --
================================================================================
*** p<0.001; ** p<0.01; * p<0.05; + p<0.1
Model 1: Endogenous variable types: Continuous (D, Y); Models: Linear (D, Y)